序
一切始于一个鼓套装。2019年夏天,我的一个朋友让我开始玩电子鼓,我全身心投入其中。有时我确实会打鼓,但我花了相当大一部分时间编写代码,使用MIDI SysEx命令与我的电子鼓进行交互。
当COVID-19大流行爆发时,我的优先事项突然变得不同,需要考虑我当地教堂的音频/视觉需求,无论我们是否远程礼拜还是考虑如何再次亲自相聚。这涉及了学习VISCA、NDI和OSC等协议(用于摄像机和音频混音器),以及与Zoom、VLC、PowerPoint、Stream Deck等更多软件相关的集成。
这些项目没有太多的业务逻辑。几乎所有的代码都是集成代码,这既令人一度感到沮丧而后又非常有力量。令人沮丧的原因是,有些协议文档含糊不清或实际上不适合我尝试实现的用途,或者它们彼此之间不一致。但它也非常有力,因为一旦你掌握了集成方面,你可以借助多个强大的工具非常轻松地编写有用的应用程序。
尽管我在过去几年的经验主要是本地集成,但与Web API相关的工作也存在着类似的令人沮丧和鼓舞的平衡。我接触过的每个新的Web API都会引发一系列情感反应,包括兴奋、困惑、烦恼、接受以及最终的平和。一旦你充分理解了一个强大的API,你会感觉自己就像一个壮丽交响乐团的指挥,随时准备演奏任何你提供的音乐,即便有时在指挥的时候会出现一些莫名其妙的问题。
这本书本身并不会改变这一点。它只是一本书。但如果你阅读它并遵循其指导,你可以帮助改善用户的体验。如果有很多人阅读它并遵循它的指导,我们可以共同推动更一致和不那么令人沮丧的Web API体验。
重要的是要理解这本书的价值不仅仅是其各个方面的总和。对于JJ所深入探讨的任何一个方面,任何一个团队都可以做出合理的选择(尽管可能会忽略这里指出的某些特殊情况)。由于上下文的有限要求,该选择甚至可能比本书中提供的建议更适合特定情况。这种方法实现了大量局部最佳决策,但整体局面高度分散,甚至在同一公司的API之间可能采用了几种不同的方法。
除了为任何特定问题提供一致性外,这本书还提供了跨API设计多个领域的一致性方法。很少有API设计师有机会深入思考这一点,我很庆幸自己能与JJ和其他人(特别是Luke Sneeringer)一起讨论本书内的许多主题。我很高兴Google在API设计方面的投资可以通过这本书和https://google.aip.dev上的AIP系统回馈给其他开发人员。
尽管我对这本书的价值有很大信心,但它并不会让API设计变得容易。相反,它消除了伴随API设计而来的许多附带复杂性,使你能够专注于对你要构建的API真正独特的方面。你仍然应该期望需要思考,而且需要深入思考,但要有信心,思考的结果可以是一个令人愉快的API。你的用户可能永远不会明确地感谢你;一个良好设计的API通常需要付出大量辛勤劳动。但你可以放心,用户们不会经历即使API能正常工作但仍然感觉使用不适的烦恼。
将这本书视为一个脚凳,帮助你的API成为一个为其他人提供支持的巨人。
——Jon Skeet, Staff Developer Relations Engineer, Google
前言
在学校,我们学习计算机科学的方式与我们学习物理定律的方式相似。我们使用大O符号分析运行时间和空间复杂性,学习各种排序算法的工作原理,探讨不同的二叉树遍历方法。所以你可以想象,毕业后,我期望我的日常工作主要是科学性和数学性质的。但令我惊讶的是,实际情况并非如此。
事实证明,我需要做的大部分工作更多地涉及设计、结构和美学,而不是数学和算法。我从不需要考虑要使用哪种排序算法,因为通常会有一个库来处理这个问题(通常类似于array.sort())。然而,我确实需要仔细思考我将创建的类,这些类上将存在哪些函数,以及每个函数将接受哪些参数。而这比我预期的要困难得多。
在现实世界中,我了解到完全优化的代码远不如良好设计的代码有价值。而这对于Web API来说尤为重要,因为它们通常有更广泛的受众和更多不同的用例。
但这引发了一个问题:什么是“良好设计”的软件?什么是“良好设计的Web API”?相当长一段时间,我不得不依赖于零散收集的资源来回答这些问题。对于某些主题,可能会有一些有趣的博客文章,探讨了当今一些常用的替代方案。对于其他主题,可能会有一些在Stack Overflow上特别有用的答案,可以指导我朝着正确的方向前进。然而,在许多情况下,关于所讨论主题的材料相对较少,我只能试图自己尝试给出答案,并希望同事们不会太讨厌它。
经过多年的这种经历(并携带着一个封面上写着“可怕的API问题”的笔记本),我最终决定是时候把我收集到的所有信息写下来,而且这些信息都是我亲身验证过的。一开始,这只是我和Luke Sneeringer为Google制定的一套规则,最终成为了AIP.dev。但这些规则有点像法律条文;它们告诉你应该怎么做,但没有解释为什么应该那样做。在经过大量研究和反复自问这个问题后,我写下这本书,不仅要呈现这些规则,还要解释为什么要这样做。
如果这本书是解决世界API设计问题的终极解决方案将会非常棒,但很不幸,我认为情况并非如此。原因很简单:就像建筑一样,任何类型的设计通常都是主观看法。这意味着有些人可能认为这些建议非常出色和优雅,会在今后的所有项目中使用它们。与此同时,也有一些人可能认为这本书呈现的设计是丑陋且过于限制性的,将其视为构建Web API时不应该采用的示例。因为我无法让每个人都满意,我唯一的目标就是提供一套经过实战验证的指南,以及为什么它们看起来这样的合乎逻辑的解释。
无论你是将它们用作跟随的示例还是要避免的示例,都由你决定。至少,我希望本书涵盖的主题引发尽量多的讨论,并激发人们未来更多探索API设计这个充满魅力和复杂的领域。
致谢
与我大部分的工作一样,这本书是许多不同人的贡献的结果。首先,我要感谢我的妻子Ka-el,在我艰难地完成这本手稿的最后工作时,倾听我发泄和抱怨。如果不是她坚定的支持,这本书可能已经被放弃。此外,许多其他人也发挥了类似的作用,包括Kristen Ranieri、Becky Susel、Janette Clarke、Norris Clarke、Tahj Clarke、Sheryn Chan、Asfia Fazal和Adama Diallo,我非常感激他们。
一支核心的API爱好者团队在审查和讨论本书涵盖的主题以及提供高级指导方面发挥了关键作用。特别要感谢Eric Brewer、Hong Zhang、Luke Sneeringer、Jon Skeet、Alfred Fuller、Angie Lin、Thibaud Hottelier、Garrett Jones、Tim Burks、Mak Ahmad、Carlos O’Ryan、Marsh Gardiner、Mike Kistler、Eric Wheeler、Max Ross、Marc Jacobs、Jason Woodard、Michael Rubin、Milo Martin、Brad Meyers、Sam McVeety、Rob Clevenger、Mike Schwartz、Lewis Daly、Michael Richards和Brian Grant多年来的帮助。
许多其他人通过他们自己独立的工作间接地为这本书做出了贡献,为此我必须感谢Roy Fielding、"四人帮"(Erich Gamma、Richard Helm、Ralph Johnson和John Vlissides)、Sanjay Ghemawatt、Urs Hoelzle、Andrew Fikes、Sean Quinlan和Larry Greenfield。我还要感谢Stu Feldman、Ari Balogh、Rich Sanzi、Joerg Heilig、Eyal Manor、Yury Izrailevsky、Walt Drummond、Caesar Sengupta和Patrick Teo在Google探讨这些主题时的支持和指导。
特别感谢Dave Nagle,他一直是我在广告、云、API等领域的支持者,鼓励我走出舒适区,超越自己。还要感谢Mark Chadwick,在10年前,他帮助我克服了在API设计中的冒名顶替综合症。他的建设性反馈和亲切的话语是我决定深入研究计算机科学中这个有趣领域的重要原因之一。此外,特别感谢Mark Hammond,他首次教会我质疑一切,即使这让人感到不适。
另外没有Manning的编辑团队的支持,这个项目是不可能完成的。特别要感谢Mike Stephens和Marjan Bace,他们批准了这本书的最初构想,以及Christina Taylor,她一直陪伴我完成另一个长期项目。我还感激Al Krinker提供的详细章节审查;我的项目编辑Deirdre Hiam;副本编辑Michele Mitchell;校对员Keri Hales;以及审阅编辑Ivan Martinovic´。感谢Manning的所有人帮助实现这个项目。
致所有审阅者:Akshat Paul、Anthony Cramp、Brian Daley、Chris Heneghan、Daniel Bretoi、David J. Biesack、Deniz Vehbi、Gerardo Lecaros、Jean Lazarou、John C. Gunvaldson、Jorge Ezequiel Bo、Jort Rodenburg、Luke Kupka、Mark Nenadov、Rahul Rai、Richard Young、Roger Dowell、Ruben Vandeginste、Satej Kumar Sahu、Steven Smith、Yul Williams、Yurii Bodarev和Zoheb Ainapore,感谢你们的建议帮助让这本书变得更好。
关于本书
《API设计模式》是为了提供一组安全、灵活、可重用的构建Web API的模式而编写的。它首先涵盖了一些通用的设计原则,然后基于这些原则展示了一组设计模式,旨在为构建API时常见场景提供简单的解决方案。
关于本书的读者
《API设计模式》适用于任何正在构建或计划构建Web API的人,尤其是那些打算将API公开使用的人。熟悉一些序列化格式(例如JSON、Google Protocol Buffers或Apache Thrift)或常见的存储范式(例如关系数据库模式)当然很有帮助,但并非必需。如果您已经熟悉HTTP及其各种方法(例如GET和POST),那将是一个额外的优势,因为在本书的示例中,HTTP是首选的传输方式。如果您在设计API时遇到问题并且在思考:“我相信一定有人已经解决了这个问题”,那么这本书就适合您。
本书的组织结构:一份路线图
这本书分为六个部分,前两个部分涵盖了API设计中的更一般性主题,接下来的四个部分专注于设计模式本身。第一部分开篇为本书的其余内容做了铺垫,提供了一些关于Web API以及将来将应用于这些Web API的设计模式的定义和评估框架。
- 第1章首先定义了我们所说的API以及API为什么重要。它还提供了一种框架,用于评估一个API的质量。
- 第2章扩展了第1章的内容,探讨了如何将设计模式应用于API,并解释了它们对于任何构建API的人都有用。它涵盖了API设计模式的基本结构,以及如何使用这些设计模式之一可以带来更好API的短期案例研究。
第2部分旨在进一步加强第1部分建立的基础,概述了在构建任何API时应考虑的一些通用设计原则。
- 第3章探讨了API中可能需要命名的各种组件以及在选择它们的名称时需要考虑的因素。本章还展示了尽管似乎是表面问题,但命名对于API设计至关重要。
- 第4章深入研究了较大的API,其中可能存在多个相互关联的资源。本章探讨了在确定资源及其关系时需要考虑的一系列问题,并涵盖了一些实例说明了需要注意规避的事项。
- 第5章探讨了API中应如何使用不同的数据类型以及这些数据类型的默认值。本章涵盖了最常见的数据类型,如字符串和数字,以及更复杂的可能性,如映射和列表。
第3部分从适用于几乎所有API的基本模式开始对设计模式进行详细介绍。
- 第6章仔细探讨了API的用户如何识别资源,深入研究了诸如墓碑标记(tombstoning)、字符集(character set)和编码(encodings)以及使用校验和(checksums)来区分缺失和无效ID等标识符的底层细节。
- 第7章详细概述了Web API的不同标准方法(get, list, create, update, delete)应如何工作。它还解释了为什么每个标准方法在所有资源上的行为方式都应该完全相同,而不是因应每个资源的独特特性而有所不同。
- 第8章扩展了两个特定的标准方法(get,update),以解释用户如何与部分而不是整个资源进行交互。它解释了为什么这是必要且有用的(对用户和API都是如此),以及如何在最小干扰的情况下保持对此功能的支持。
- 第9章进一步介绍自定义方法,为在API中实现任何类型的操作提供了可能。本章特别解释了何时使用自定义方法是有意义的(以及何时不是),以及如何在自己的API中做出这一决策。
- 第10章探讨了一种独特的情景,即API方法可能不是瞬时(同步)的,以及如何为具有耗时操作——LROs(long-running operations)的用户方便地提供支持。它探讨了LROs的工作原理以及可以由LROs支持的所有方法,包括暂停、恢复和取消作业。
- 第11章涵盖了一种可重复执行作业的概念,有点像Web API的cron作业。它解释了如何使用执行资源(Execution resources)以及如何按计划或按需执行这些工作。
第4部分着重关注资源以及它们之间的关系,有点像对第4章的更广泛探讨。
- 第12章解释了如何将相关数据的小型、孤立部分隔离到单例子资源中。本章详细介绍了这种做法适用以及不适用的情况。
- 第13章概述了Web API中的资源应如何使用引用指针(reference pointer)或内联值(inline value)存储对其他资源的引用。本章还解释了如何处理特殊情况,例如随时间推移引用数据发生变化时的更新或级联删除。
- 第14章扩展了资源之间的一对一关系,并解释了如何使用关联资源(association resources)表示多对多关系。本章还涵盖了关于这些关系的元数据存储。
- 第15章探讨了在处理多对多关系时,使用添加和移除的快捷方法作为替代方案,而不依赖于关联资源。本章还涵盖了在使用这些方法时的一些权衡以及为什么它们可能不总是理想的选择。
- 第16章探讨了多态(polymorphism)的复杂概念,其中同名变量可以具有各种不同类型。本章涵盖了如何处理API资源上的多态字段,以及为什么应避免多态方法。
第5部分开始探讨面向整个资源集合的交互。
- 第17章解释了在API中如何复制或移动资源。本章解决了很多复杂的问题如处理外部数据、从不同的父级继承元数据以及应如何处理子资源。
- 第18章探讨了如何调整标准方法(get, create, update, delete)以在一个时间内操作多个资源的集合,而不是单个资源。本章还涵盖了一些棘手的问题,例如应如何返回结果以及如何处理部分失败。
- 第19章扩展了第17章中批量删除方法的概念以删除与特定过滤器(filter)匹配的资源。本章还探讨了如何解决一致性问题和避免数据意外破坏的最佳实践。
- 第20章仔细研究了非资源数据的注入。本章介绍了匿名写入(anonymous write)的使用和一致性问题,并探讨了在适用API时如何权衡此类匿名数据注入。
- 第21章解释了如何依赖于不透明的页面令牌(page tokens),使用分页(pagination)来处理大型数据集的浏览。本章还演示了如何在单个大型资源内使用分页。
- 第22章讨论了如何处理应用筛选条件(filter criteria)以列出资源,并以最佳方式在API中表示这些筛选条件。这直接与第19章中讨论的主题相关。
- 第23章探讨了如何处理资源的导入(import)和导出(export),以及相对于备份和还原操作的导入和导出操作的微妙差异。
第6部分关注API中相对不那么令人兴奋的安全(safety)和安全性(security)领域。这意味着确保API免受攻击者的威胁,同时还要确保API提供的方法不容易受到用户自己的错误行为的影响。
- 第24章探讨了版本控制的话题以及不同版本之间兼容性的含义。本章深入探讨了兼容性作为一个光谱的概念,以及在API中保持一致的兼容性政策定义的重要性。
- 第25章开始通过提供一种软删除(soft deletion)模式来保护用户免受其自身的威胁,允许资源从视图中删除而不完全从系统中删除。
- 第26章试图通过使用请求标识符(request identifiers)来保护系统免受重复操作的影响。本章探讨了使用请求ID的风险,以及一种确保在大规模系统中正确处理这些ID的算法。
- 第27章重点讨论允许用户在API中执行操作之前获得操作预览的验证性请求(validation requests)。本章还探讨了如何处理更复杂的问题,如实际请求和验证请求同时存在的副作用。
- 第28章引入了资源修订(resource revisions)的概念,作为跟踪变更的一种方式。本章还涵盖了一些基本操作例如还原到以前的修订,以及更复杂的话题例如如何将修订应用于层级结构中的子资源。
- 第29章提供了一种用于在API请求需要重试(retry)时通知用户的模式。本章还包括了关于不同的HTTP响应代码的准则,以及它们是否适合进行重试。
- 第30章探讨了如何验证单个请求以及在验证API用户时需要考虑的不同安全标准。本章提供了一个符合安全最佳实践的数字签名API请求规范,以确保API请求具有可验证的来源和完整性,且不会在未来被否认(repudiated)。
关于代码
本书包含许多源代码示例,既有带编号的代码块,也有与普通文本并排的代码。在这两种情况下,源代码都使用等宽字体进行格式化,以与普通文本区分开来。有时,代码也会用粗体显示,以突出显示与章节中之前步骤中的代码不同的代码,例如当新功能添加到现有代码行时。
在许多情况下,原始源代码已经重新格式化,我们添加了换行符并重新排列缩进,以适应书中可用的页面空间。即使这样还不够,代码块中还包括了行连续标记 (➥)。此外,在源代码中的注释通常在文本中描述代码时会被删除。许多代码块都附有代码注释,强调重要概念。
经过与初期读者和审阅团队的广泛讨论,我决定使用TypeScript作为标准语言。首先,对于那些熟悉动态语言(如JavaScript或Python)和静态语言(如Java或C++)的人来说,TypeScript很容易理解。此外,尽管它可能不是每个人的最爱,也不是所有读者都能立刻编写自己的TypeScript代码,但代码片段可以被视为伪代码,大多数软件开发人员应该能够理解其含义。
在使用TypeScript定义API时,有两个方面需要考虑:资源和方法。对于前者,TypeScript的原语(如接口)在定义API资源的模式(schemas)时有很强的表达力,使得API定义通常非常简短,几乎总是可以放在几行之内结束。因此,所有API资源都被定义为TypeScript接口,这还具有使JSON表示变得非常明显的额外优势。
对于API方法,问题会稍微复杂一些。在这种情况下,我选择使用TypeScript的抽象类来表示整体API本身,使用抽象函数来定义API方法,这是一种通常用于Google的Protocol Buffers的RPC的约定。这样能够仅定义API方法,而无需担心底层实现。
在考虑API方法的输入和输出时,我决定再次依靠Protocol Buffers,考虑使用请求(request)和响应(response)接口。这意味着在大多数情况下,会有表示这些输入和输出的接口,以API方法的名称为基础,附加 -Request 或 -Response 后缀(例如,CreateChatRoomRequest 用于 CreateChatRoom API 方法)。
最后,由于这本书在很大程度上依赖于RESTful概念,必须有一种将这些RPC映射到URL(以及HTTP方法)的方法。为此,我选择使用TypeScript装饰器作为各种API方法的注释,每个不同HTTP方法会有一个注释(例如,@get、@post、@delete)。为了指示API方法应映射到的URL路径,每个装饰器都接受一个持请求接口中变量通配符的模板字符串。例如,@get("/{id=chatRooms/*}") 会在请求中填充ID字段。在这种情况下,星号表示一个除了斜杠字符以外的任何值的占位符。
尽管使用OpenAPI规范来定义所有这些设计模式可能是很好的选择,但有一些问题可能对这本书的读者不太友好。首先,OpenAPI规范主要是供计算机(例如,代码生成器、文档渲染器等)使用的,因为这本书的目标是向其他API设计师传达复杂的API设计主题,所以OpenAPI似乎并不是最好的选择。
其次,无论是使用YAML还是JSON格式,OpenAPI都相当冗长。不幸的是,使用OpenAPI来表示这些复杂主题完全是可能的,但并不是最简洁的选择,会带来很多额外的内容,而未能添加太多价值。
最终,在OpenAPI、Protocol Buffers和TypeScript之间,初期读者和审阅者明确反馈,对于这种特定用例TypeScript是最佳选择。请记住,我并不主张人们使用TypeScript来定义他们的API。这只是这个项目的一个非常合适的选择。
线上论坛
购买《API设计模式》将包括免费访问由Manning出版社运营的私人网络论坛,您可以在论坛上对书籍提出评论、提问技术问题,并得到作者和其他用户的帮助。要访问论坛,请前往 https://livebook.manning.com/book/api-design-patterns/welcome/v-7 。您还可以了解更多关于Manning论坛以及行为规则的信息,链接是 https://livebook.manning.com/#!/discussion 。 Manning对我们的读者承诺提供一个有意义的平台,使个体读者之间以及读者与作者之间可以进行深入的对话。这并不意味着作者会有特定数量的参与承诺,作者对论坛的贡献仍然是自愿的(且未获报酬)。我们建议您尝试向作者提出一些具有挑战性的问题,以保持他的兴趣!只要这本书还在印刷中,论坛和以前的讨论存档将从出版商的网站上获得访问权限。
其他线上资源
要进一步阅读有关API设计相关的内容,请访问 https://aip.dev,该网站详细介绍了许多类似的主题。
关于作者
JJ GEEWAX是Google的一名软件工程师,专注于实时支付系统、云基础设施和API设计。他还是《Google Cloud Platform in Action》一书的作者,同时也是AIP.dev的联合创始人,这是一个由Google发起的面向整个行业的API设计标准协作项目。他与妻子Ka-el和儿子Luca一同居住在新加坡。
关于封面图片
《API Design Patterns》封面上的图案标题为“维也纳的版画商”(Marchand d’Estampes à Vienne)。这幅插图选自Jacques Grasset de Saint-Sauveur(1757–1810)的《不同国家的服装》(Costumes de Différents Pays)系列,该系列于1797年在法国出版。每幅插图都经过精细手绘和上色。Grasset de Saint-Sauveur的丰富系列让我们鲜活地想起,仅仅200年前,世界各地的城镇和地区在文化上有多么不同。人们相互隔离,使用不同的方言和语言。在街头或乡村,只需看他们的服装就很容易辨别出他们来自何处以及他们的职业或社会地位。
自那时以来,我们的着装方式发生了变化,当时如此丰富的地区多样性已经逐渐消失。现在很难区分不同大陆的居民,更不用说不同城镇、地区或国家的居民了。也许我们已经用文化多样性换取了更丰富的个人生活,当然还有更多样化和快节奏的技术生活。
在现在很难将一本计算机书与另一本区分开的时候,Manning通过基于两个世纪前地区生活的丰富多样性来庆祝计算机行业的创新和主动性,这些多样性是由Grasset de Saint-Sauveur的图片重现生活。
概述
API设计是复杂的。毕竟,如果它很容易,那么可能根本不需要这本书。但在我们开始探讨工具和模式以使API设计变得更加可管理之前,我们首先需要就一些基本术语达成一致,以及对这本书可以期望什么有一些共识。在接下来的两章中,我们将涵盖一些入门材料,这些材料将成为我们在本书的其余部分建立的基础。
我们将从第1章开始,详细定义我们所说的API是什么。更重要的是,我们将探讨优秀的API是什么样的,以及如何将其与糟糕的API区分开来。然后在第2章中,我们将更仔细地研究我们所说的设计模式是什么,以及本书其余部分所概述的模式的结构,最终目标是依靠这些设计模式构建一致的优秀API。
第一章 什么是API
本章涵盖:
- 什么是接口
- 什么是API
- 什么是资源导向
- 什么是“好”的API
很可能,拿起这本书的人已经对API的上层概念有所了解。此外,你可能已经知道API代表应用程序编程接口,因此本章的重点将更详细地解释这些基础知识,以及它们为什么重要。让我们更仔细地看看API的这个概念。
1.1 什么是web API
API(应用程序编程接口)定义了计算机系统相互交互的方式。鉴于不可能有系统存在于真空中,API无处不在也就不足为奇了。我们可以在我们使用的语言包管理器中找到API(例如,提供类似function encrypt(input: string): string的加密库)。在我们自己编写的代码中也可以找到API,即使他们不是为他人使用而产生。但有一种特殊类型的API是专为通过网络公开并远程为他人使用的,这正是本书的重点,通常被称为“Web API”。
Web API在许多方面都很有趣,但这个特殊类别最有趣的方面可能是建立API的人有很大的控制权,而使用Web API的人相对较少。当我们使用库时,我们处理库本身的本地副本,这意味着构建API的人可以随心所欲地做任何他们想做的事情,而不会伤害用户。Web API则不同,因为没有副本。相反,当Web API的构建者进行更改时,这些更改会被强制应用于用户,无论更改是否源自用户要求。
例如,想象一下一个允许你加密数据的Web API调用。如果负责这个API的团队决定在加密数据时使用不同的算法,你实际上没有选择的余地。在调用加密方法时,你的数据将使用最新的算法进行加密。在一个更极端的例子中,团队可以决定完全关闭API并忽略你的请求。那时,你的应用程序将突然停止工作,你无法做太多事情。图1.1展示了这两种情况。
图1.1 处理Web API时可能出现的面向消费者的体验
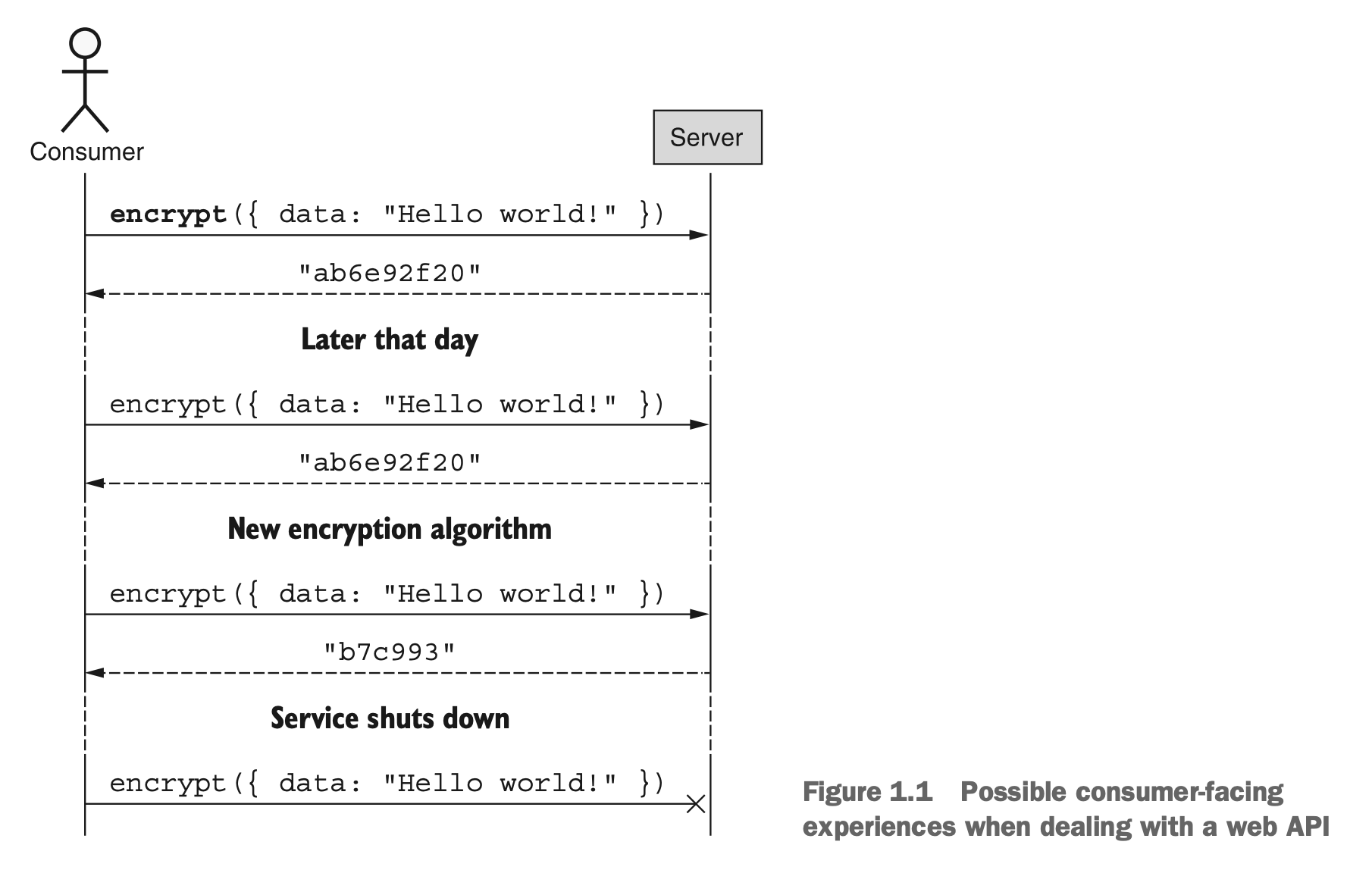
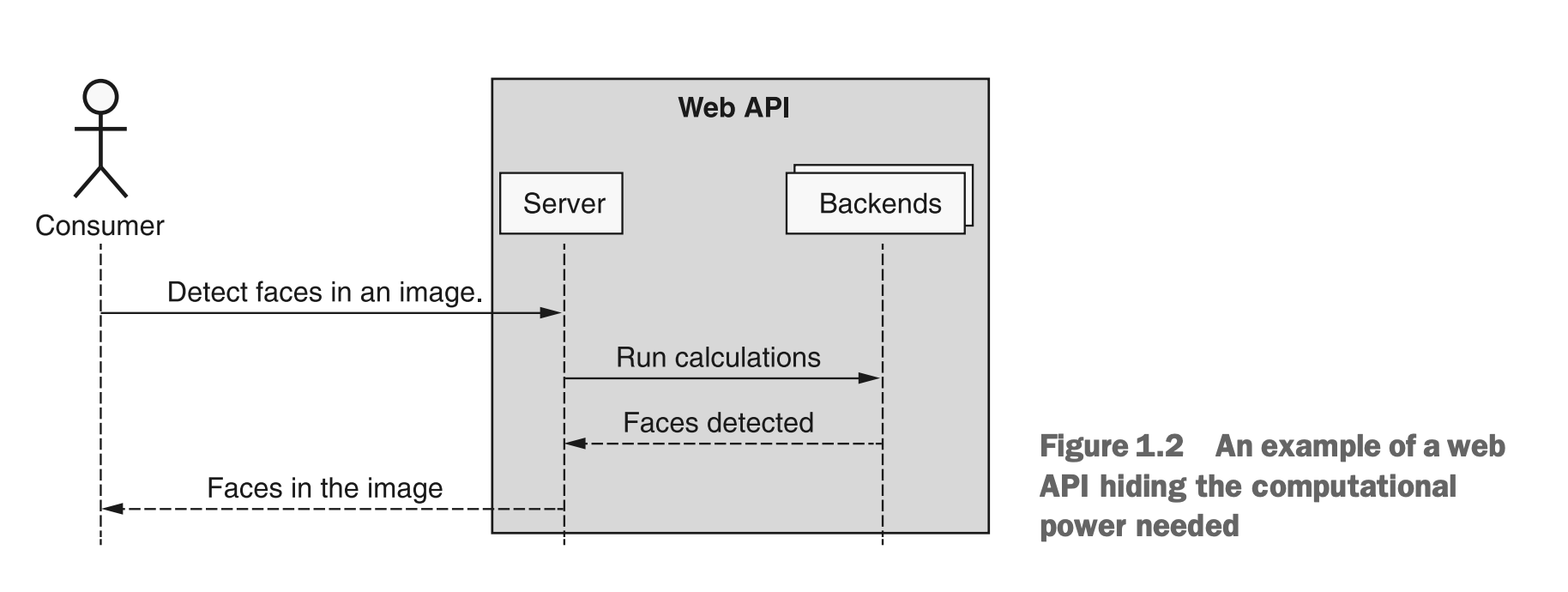
然而,对于API的使用者来说,Web API的缺点通常是那些构建API的人的主要优势:他们能够完全掌控API。例如,如果加密API使用了一个绝密的新算法,构建它的团队可能不希望将那段代码以库的形式随意分享给全世界。相反,他们可能更喜欢使用Web API,这将允许他们展示超级秘密算法的功能,而不会泄露他们宝贵的知识产权。还有一些情况,某个系统可能需要非凡的计算能力,如果部署为库并在家用计算机或笔记本电脑上运行,那么运行时间将太长。在这些情况下,例如在许多机器学习API中,构建Web API允许你展示强大的功能,同时将计算需求对使用者隐藏起来,如图1.2所示。
图1.2 一个隐藏所需计算能力的Web API的示例
既然我们了解了API(特别是Web API)是什么,这就引发了一个问题:它们为什么如此重要呢?
1.2 为什么API很重要
虽然将软件设计和构建仅供人类使用并不罕见,这本身并没有根本性问题。然而,过去几年,我们越来越多地关注自动化,我们的目标是构建能够以更快的速度执行人类工作的计算机程序。不幸的是,正是在这一点上,“仅供人类使用”的软件成为了一个问题。
当我们专门为人类使用设计某物,其中我们的互动涉及鼠标和键盘时,我们倾向于将系统的布局和视觉方面与原始数据和功能方面混为一谈。这是有问题的,因为很难向计算机解释如何与图形界面进行交互。而且这个问题变得更加严重,因为改变程序的视觉方面也可能要求我们重新教导计算机如何与这个新的图形界面进行交互。实际上,虽然对我们来说这些变化可能只是表面上的,但对计算机来说却是完全无法识别的。换句话说,对于计算机来说,不存在“仅仅是表面上的”这种东西。
API是专门为计算机设计的接口,具有使计算机能够轻松使用它们的重要特性。例如,这些接口没有视觉方面的内容,因此无需担心表面上的变化。而且这些接口通常以“兼容”(compatible)的方式演进(参见第24章),因此在面对新的变化时不需要重新教导计算机任何内容。简而言之,API提供了一种以安全和稳定的方式与计算机进行交互所需的语言。
但这并不仅限于简单的自动化。API还打开了组合(composite)的大门,使我们能够像乐高积木一样处理功能,将各个部分组合在一起,以新颖的方式构建远大于其各部分之和的东西。为了完成这个循环,这些新的API组合也可以加入可重复使用的构建块的行列,从而实现更复杂和非凡的未来项目。
但这引出了一个重要问题:我们如何确保我们构建的API像乐高积木一样相互契合?让我们首先看看其中一种策略,即资源导向(resource orientation)。
1.3 什么是资源导向API
许多现今存在的Web API有点像仆人:你要求它们做某事,它们就会去做。例如,如果我们想要获取我们家乡的天气,我们可以像对待仆人一样命令Web API来predictWeather(postalCode=10011)。通过调用预配置的子程序或方法来命令另一台计算机执行某项任务的这种方式通常被称为进行“远程过程调用”(RPC),因为我们实际上是在调用一个库函数(或过程),以在潜在遥远的另一台计算机上执行(或远程执行)。像这样的API主要关注正在执行的操作。也就是说,我们考虑计算天气(predictWeather(postalCode=...))或加密数据(encrypt(data=...))或发送电子邮件(sendEmail(to=...))等,每个都强调“正在做”某事。
那么为什么不是所有API都是RPC导向的呢?其中一个主要原因与“有状态性”(statefulness)的概念有关,因为API调用可以是“有状态的”或“无状态的”。当API调用可以独立于所有其他API请求而进行,而且没有任何额外的上下文或数据时,被认为是无状态的。例如,用于预测天气的Web API调用只涉及一个独立的输入(邮政编码),因此被视为无状态。另一方面,一个Web API可以存储用户喜欢的城市并提供这些城市的天气预报,这个API在运行时不需要输入,但需要用户已经存储了他们感兴趣的城市。因此,这种涉及其他先前请求或先前存储的数据的API请求被视为有状态。事实证明,RPC风格的API非常适用于无状态功能,但当我们引入有状态的API方法时,它们往往不太合适。
注意:如果你熟悉REST,现在可能是一个好时机指出,这一节不是关于REST和RESTful API特定的,而更普遍地涉及强调“资源”的API(正如大多数RESTful API所做的)。换句话说,虽然与REST的主题有很多重叠,但这一节比仅仅是REST要更通用一些。
为了理解这一点,让我们来看一个用于预订航班的有状态API的示例。在表1.1中,我们可以看到一系列用于与航空旅行计划进行交互的RPC,涵盖了安排新预订、查看现有预订和取消不需要的旅行等操作。
表1.1 示例航班预订API方法摘要
| 方法 | 描述 |
|---|---|
| ScheduleFlight() | 预定新航班 |
| GetFlightDetails() | 展示特定航班详细信息 |
| ShowAllBookings() | 展示当前所有预定信息 |
| CancelReservation() | 取消预定 |
| RescheduleFlight() | 更改已预定航班 |
| UpgradeTrip() | 升级舱位 |
这些RPC方法都相当具有描述性,但我们无法避免需要记住这些API方法,每个方法都与其他方法略有不同。例如,有时候一个方法涉及“航班”(例如,RescheduleFlight()),而其他时候操作“预订”(例如,CancelReservation())。我们还需要记住使用了多少个同义词形式的操作。例如,我们需要记住如何查看所有的预订,是使用ShowFlights()、ShowAllFlights()、ListFlights()还是ListAllFlights()(在本例中应该使用ShowAllFlights())。但是,我们该如何解决这个问题呢?答案在于标准化。
资源导向(resource orientation)旨在通过为API设计提供两个方面的标准化模块来帮助解决这个问题。首先,资源导向API依赖于“资源”的概念,这些资源是我们存储和互动的关键概念,标准化了API管理的“事物”。其次,与使用任意RPC名称执行我们能想到的任何操作不同,资源导向API将操作限制为一小组标准操作(见表1.2),这些操作适用于每个资源,以形成API中的有用操作。从稍微不同的角度来看,资源导向API实际上只是RPC式API的一种特殊类型,其中每个RPC都遵循清晰和标准化的模式:<StandardMethod><Resource>()。
表1.2 标准方法及其含义
| RPC | 描述 |
|---|---|
| Create | 创建新资源 |
| Get | 获取并展示特定资源信息 |
| List | 获取并展示当前所有资源列表 |
| Delete | 删除一个资源 |
| Update | 更新一个资源 |
如果我们选择采用这种特殊且有限的RPC方法,那意味着与表1.1中所示的各种不同RPC方法相比,我们可以创建一个单一的资源(例如,FlightReservation),并使用表1.3中所示的一组标准方法获得等效的功能。
表1.3 标准方法应用于“航班”资源
| 标准方法 | 资源 | 方法名 | ||
|---|---|---|---|---|
| Create | X | FlightReservation | = | CreateFlightReservation() |
| Get | X | FlightReservation | = | GetFlightReservation() |
| List | X | FlightReservation | = | ListFlightReservation() |
| Delete | X | FlightReservation | = | DeleteFlightReservation() |
| Update | X | FlightReservation | = | UpdateFlightReservation() |
标准化显然更有组织,但这是否意味着所有的面向资源的API都严格优于面向RPC的API?实际上并非如此。对于某些情况,面向RPC的API可能更适合(特别是在API方法是无状态的情况下)。然而,在许多其他情况下,面向资源的API对于用户来说会更容易学习、理解和记住。这是因为资源导向API提供的标准化使您可以轻松地将已知的东西(例如,一组标准方法)与您可以轻松学习的东西(例如,新资源的名称)相结合,从而立即开始与API互动。更具数值意义的说法是,如果您熟悉,比如,五种标准方法,那么由于可靠模式的力量,学习一个新资源实际上等同于学习五个新的RPC方法。
显然,重要的是要指出并不是每个API都相同,以“要学习东西的多少”来定义API的复杂性有点粗糙。另一方面,这里有一个重要的原则在起作用:模式的力量(the power of patterns)。通常,学习可组合的模块并将它们组合成遵循一种固定模式的更复杂的事物,比学习每次都遵循自定义设计的复杂事物更容易。由于资源导向API利用经过验证的设计模式的强大力量,它们通常更容易学习,因此比其面向RPC的等效物“更好”。但这引出了一个重要问题:这里的“更好”是什么意思?我们如何知道一个API是“好”的?甚至“好”意味着什么?
1.4 什么是“好”的API
在我们探讨使API变得更“好”之前,首先需要深入了解为什么我们需要一个API。换句话说,建立API的目的是什么?通常,这可以归结为两个简单的原因:
- 我们拥有一些用户想要使用的功能。
- 这些用户希望以编程方式使用这些功能。
举个例子,我们可能拥有一套出色的系统,可以将文本从一种语言翻译成另一种语言。世界上可能有很多人想要拥有这种能力,但光有这一点还不够。毕竟,我们可以推出一个翻译手机应用程序而不是一个API。所以,那些想要这个功能的人必须还想编写一个使用它的程序,我们才有必要建立一个API。有了这两个标准,我们再来思考一个好的API应该具有什么特质呢?
1.4.1 操作性
首先最重要的部分是,无论最终的界面是什么样的,整个系统必须是可操作的。换句话说,它必须执行用户实际想要的功能。如果这是一个将文本从一种语言翻译成另一种语言的系统,那么它必须确实能够执行这个功能。此外,大多数系统很可能会有许多非操作性要求(nonoptional)。例如,如果我们的系统将文本从一种语言翻译成另一种语言,可能会有与延迟(例如,翻译任务应该花费几毫秒,而不是几天)或准确性(例如,翻译不应误导)等非操作性要求相关的事项。我们说,这两个方面共同构成了系统的操作性方面。
1.4.2 表达性
如果一个系统具备某种功能很重要,那么同样重要的是,该系统的接口允许用户清晰而简单地表达他们想要做的事情。换句话说,如果系统将文本从一种语言翻译成另一种语言,那么API应该设计得如此清晰和简单,以便有一种明确的方式来实现这一目标。在这种情况下,可能会有一个名为TranslateText()的RPC。这种事情可能听起来很明显,但实际上可能比看起来更复杂。
比如,一个API已经支持某些功能,但由于我们的疏忽,我们没有意识到用户需要这些功能,因此没有构建好的表达方式使用户能够轻松访问该功能。这种情况通常表现为用户会采取一些变通方法来访问已经支持的隐藏功能。例如,如果一个API提供将文本从一种语言翻译成另一种语言的能力,那么可能有用户会迫使API充当语言检测器,即使他们实际上并不真正想翻译任何东西。如清单代码1.1所示。正如你所想的,如果用户有一个名为DetectLanguage()的RPC会更好。
代码1.1 使用 TranslateText API 方法来实现检测语言的功能
function detectLanguage(inputText: string): string {
const supportedLanguages: string[] = ['en', 'es', ... ];
for (let language of supportedLanguages) {
// 这里假定API定义了一个`TranslateText`方法,该方法接受输入文本和目标语言以进行翻译。
let translatedText = TranslateApi.TranslateText({
text: inputText,
targetLanguage: language
});
// 如果翻译后的文本与输入文本相同,那么我们知道这两种语言是相同的。
if (translatedText == inputText) {
return language;
}
}
// 如果我们找不到与输入文本相同的翻译文本,我们将返回null,表示我们无法检测输入文本的语言。
return null;
}
正如这个例子所示,支持某些功能但不让用户轻松访问这些功能的API不太好。另一方面,富有表现力的API允许用户清晰地表达他们想要什么(例如,翻译文本)甚至如何完成任务(例如,“在150毫秒内完成,准确率达到95%”)。
1.4.3 简洁性
与任何系统的可用性相关的最重要的事情之一是简洁性。有时候人们会认为简洁是减少API中的事物(例如,RPC、资源等)的数量,但不幸的是,这种情况很少发生。例如,一个API可以依赖于一个处理所有功能的单一ExecuteAction()方法;然而,这实际上并没有简化任何东西。相反,它将复杂性从一个地方(大量不同的RPC)转移到另一个地方(单个RPC中的大量配置)。那么一个简洁的API究竟是什么样的呢?
与其试图过度减少RPC的数量,API应该致力于以尽可能简单的方式公开用户所需的功能,使API尽可能简洁但不过于简洁。例如,想象一下一个翻译API希望添加检测输入文本语言的功能。我们可以通过在翻译响应中返回检测到的源文本来实现这一点;然而,这仍然是一种功能混淆,因为该功能隐藏在设计用于其他目的的方法中。相反,更合理的做法是创建一个专门用于此目的的新方法,例如DetectLanguage()。(请注意,我们可能还会在翻译内容时返回检测到的语言,但这完全是为了另一个目的。)
关于简洁性的另一个方面关乎“常见情况”。我们将更多精力放在关注可用性上,同时为特殊情况留出余地。其目的是“让常见情况变得出色,让高级情况成为可能”。这意味着每当您添加可能会使API变得复杂以造福高级用户的功能时,最好将此复杂性对典型用户(只对常见情况感兴趣)进行充分隐藏。这样,更频繁的情景变得简单和容易,同时仍然为那些高级功能提供支持。
例如,假设我们的翻译API包括一个用于翻译文本的机器学习模型的概念,其中我们不是指定目标语言,而是选择一个基于目标语言的模型,并将该模型用作“翻译引擎”。尽管这种功能为用户提供了更大的灵活性,但它也更复杂,新的常见情况如图1.3所示。
图1.3 通过选择匹配模型进行文本翻译
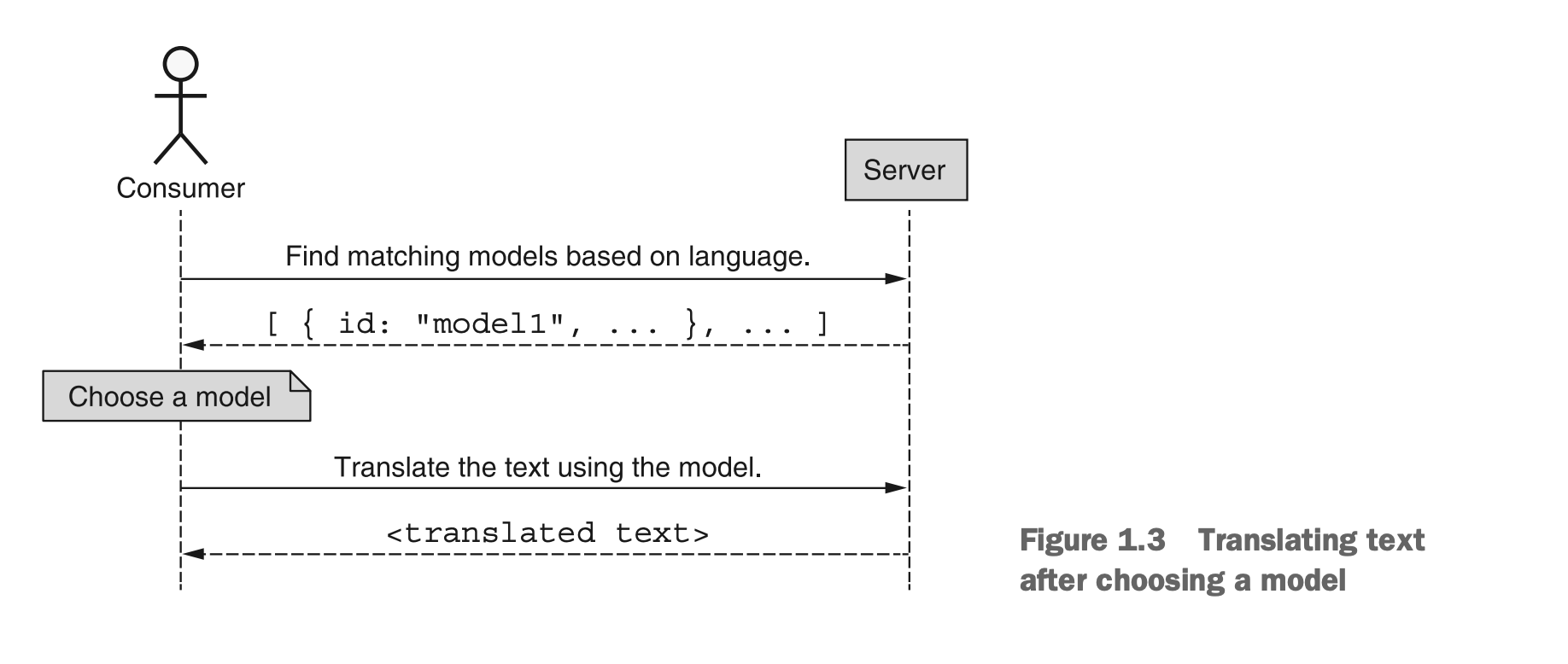
正如我们所看到的,为了支持更高级的功能,我们实际上使翻译某些文本变得更加困难。为了更清楚地看到这一点,对比代码1.2中显示的代码与简单调用TranslateText("Hello world", "es")的简洁性。
代码1.2 通过选择匹配模型进行文本翻译
function translateText(inputText: string, targetLanguage: string): string {
// 由于我们需要选择一个模型,因此首先需要知道输入文本的语言
// 为了确定这一点,我们可以依赖API提供的假设的`DetectLanguage()`方法。
let sourceLanguage = TranslateAPI.DetectLanguage(inputText);
// 一旦确定了输入和输出语言,我们可以选择任何API提供的与之匹配的模型。
let model = TranslateApi.ListModels({
filter: `sourceLanguage:${sourceLanguage}
targetLanguage:${targetLanguage}`,
})[0];
// 至此我们获取了需要的输入参数,可以调用对应方法进行翻译了。
return TranslateApi.TranslateText({
text: inputText,
modelId: model.id
});
}
我们应当如何设计这个API,以使其尽可能简洁但不过于简单,且使常见情况变得出色,同时使高级情况成为可能呢?由于常见情况涉及那些实际上并不关心特定模型的用户,我们可以通过设计API,使其接受targetLanguage或modelId中的任一个。高级情况仍然可以工作(实际上,清单1.2中显示的代码仍将有效),但常见情况将显得简单得多,仅依赖于targetLanguage参数(并使modelId参数保持未定义)。
代码1.3 文本翻译(常见情况)
function translateText(inputText: string,
targetLanguage: string,
modelId?: string): string {
return TranslateApi.TranslateText({
text: inputText,
targetLanguage: targetLanguage,
modelId: modelId,
});
}
现在我们对"好"的API的简洁性属性有了一些了解,让我们来看最后一点:可预测性。
1.4.4 可预测性
虽然生活中的惊喜有时可能很有趣,但API中不应该出现惊喜,无论是在接口定义还是底层行为。这有点像有关投资的老话:“如果令人兴奋,那么你做错了。”那么我们所说的“不令人惊讶”的API是什么意思呢?
不令人惊讶的API依赖于在API表面定义和行为上应用的重复模式。例如,如果一个翻译文本的API具有一个TranslateText()方法,该方法将输入内容作为名为text的字段传递,那么当我们添加DetectLanguage()方法时,输入内容也应该称为text(而不是inputText、content或textContent)。虽然现在这可能看起来很明显,但请记住,许多API是由多个团队构建的,当提供一组选项时,字段命名的选择通常是任意的。这意味着当两个不同的人负责这两个不同的字段时,他们很可能会做出不同的任意选择。当发生这种情况时,我们最终得到一个不一致(因此令人惊讶)的API。
尽管这种不一致性可能看似微不足道,但事实证明,这些问题比它们看起来更重要。这是因为事实上,API的用户很少通过彻底阅读所有API文档来学习每一个细节。相反,用户只会阅读适当的文档来完成他们想要做的事情。这意味着如果某人学到一个请求消息中的字段称为text,那么他们几乎可以假定在另一个请求中它也是以相同的方式命名的,从而在他们已经学到的基础上对他们尚未学到的事情进行有根据的猜测。如果这个猜测失败(例如,因为另一条消息将该字段命名为inputText),他们的生产力就会受到阻碍,他们不得不停下来弄清楚为什么他们的假设失败了。
显而易见的结论是,依赖重复、可预测模式(例如,一致性地命名字段)的API更容易、更快地学习,因此更好。更复杂的模式,如我们在探讨资源导向API时看到的标准操作,也会带来类似的好处。这使我们进入了本书的整个目的:使用众所周知、明确定义、清晰(希望如此)的模式构建的API将导致可预测且易于学习的API,这会构造出总体上更“好”的API。现在,我们对API以及使其变得更好的因素有了很好的了解,让我们开始考虑在设计API时可以遵循的更高级模式。
本章总结
- 接口是定义两个系统应该如何相互交互的合约。
- API是接口的一种特殊类型,它定义了两个计算机系统如何相互交互;其有多种形式,如可下载的库和Web API。
- Web API是特殊的,因为它们在网络上暴露功能,隐藏了实现细节或功能所需的特定计算要求。
- 资源导向API是通过依赖一组标准操作(称为方法)跨有限的事物(称为资源)来减少复杂性的一种API设计方式。
- 使API“好”的因素有点模糊,但一般来说,好的API具有操作性、表达性、简洁性和可预测性。
第二章 什么是API设计模式
本章涵盖:
- 什么是API设计模式
- 为什么API设计模式很重要
- 解构API设计模式
- 使用设计模式和不使用设计模式来设计API的差异
现在,我们已经了解了API是什么以及什么是“好”的API,我们可以继续探讨在构建API时如何应用不同的模式。我们将从探讨API设计模式是什么,为什么它们很重要,以及我们将如何在后续章节中解析这些模式。最后,我们将查看一个示例API,看看如何使用预构建的API设计模式可以节省大量时间和避免潜在的麻烦。
2.1 什么是API设计模式
在我们开始探讨API设计模式之前,我们需要打下一些基础。首先从一个简单的问题开始:什么是设计模式?如果我们注意到软件设计是指为了解决问题而编写的一些代码的结构或布局,那么软件设计模式是指特定的设计可以反复应用于许多类似的软件问题,只需要进行小的调整以适应不同的情境。这意味着该模式不是我们用来解决单个问题的预构建库,而更像是解决相似结构问题的蓝图。
如果这听起来太抽象,让我们来具体化一下,想象一下我们想在后院建一个小屋。有几种不同的选择,从几百年前的做法到如今由Lowe's和Home Depot等公司提供的现代化专业方法。有很多选择,但有四种常见的选择,如下所示:
- 购买预制的小屋并放在后院。
- 购买小屋套件(设计图纸和材料)并自己组装。
- 购买一套小屋的设计图,根据需要修改设计,然后自己建造。
- 从头开始设计和建造整个小屋。
如果我们将这些与它们的软件等效物联系起来,它们将从使用现成的现成软件包一直到编写完全定制的系统来解决问题。在表2.1中,我们可以看到随着列表项目从上到下,这些选项会变得越来越困难,但从一个选项到下一个会增加越来越多的灵活性。换句话说,难度最低的灵活性最小,而难度最大的灵活性最大。
表2.1 建造小屋和构建软件系统方式的类比
| 选项 | 困难度 | 灵活度 | 对应的软件构件选项 |
|---|---|---|---|
| 购买预制的小屋 | 简单 | 无 | 直接使用现成的软件包 |
| 购买套件组装 | 比较简单 | 很小 | 自定义现成的软件包 |
| 按照现成设计图建造 | 一般 | 一般 | 从设计文档开始构建 |
| 从头设计并建造 | 困难 | 最大 | 从头设计软件系统并构建 |
软件工程师大多数情况下倾向于选择“从头开始构建”的选项。有时这是必要的,特别是在我们解决的问题是新问题的情况下。其他情况下,这个选择在成本效益分析中胜出,因为我们的问题与易用选项有足够的不同。还有一些情况下,我们可能已经知道一个库恰好解决了我们的问题(或者足够接近),因此我们选择依赖已经解决类似问题的工具。事实证明,选择介于中间的选项(定制现有软件或根据设计文档进行构建)不太常见,但却应该经常使用并会获得很好的效果。这就是设计模式的应用之处。
从上层看,设计模式是应用于软件的“按设计图纸构建”的选项。就像小屋的设计图包括尺寸、门窗的位置以及屋顶的材料一样,设计模式包括我们编写的代码的某些规格和细节。在软件中,这通常意味着指定代码的高级布局以及依赖布局来解决特定设计问题的细微差别。然而,很少有设计模式是为了完全独立使用而生的。大多数情况下,设计模式侧重于特定的组件而不是整个系统。换句话说,设计图侧重于单个方面(比如屋顶形状)或组件(比如窗户设计),而不是整个小屋。乍看之下,这可能看起来不太好,但只有在目标确实是建造一个小屋的情况下才是如此。如果您尝试构建与小屋类似但不完全相同的东西,那么拥有每个单独组件的设计图意味着您可以将它们组合在一起,精确地构建出您想要的东西,选择屋顶形状A和窗户设计B。这也适用于我们的设计模式讨论,因为每个设计模式通常侧重于系统的单个组件或问题类型,通过组装许多预设计的组件,帮助您构建出您想要的东西。
例如,如果您想要向系统添加调试日志记录,您可能只希望有一种方法来记录消息。有很多方法可以做到这一点(例如,使用一个单一的全局变量),但偶然间有一个设计模式旨在解决这个软件问题。这个模式在经典著作《设计模式》(Gamma等人,1994)中有所描述,被称为单例模式(singleton),它确保只创建一个类的实例。这个“设计图”要求一个类具有私有构造函数和一个名为getInstance()的静态方法,该方法总是返回该类的单个实例(只有在它还不存在的情况下才创建该单个实例)。这个模式本身不是全部(毕竟,拥有一个什么都不做的单例类有什么用呢?);但是,它是在需要解决这个小型问题的情况下要遵循的一个经过明确定义和经过充分测试的模式,即始终有一个类的单个实例。
现在我们知道了通常的软件设计模式是什么,我们必须问一个问题:什么是API设计模式?根据第1章中对API的描述,API设计模式只是将软件设计模式应用于API而不是所有软件。这意味着API设计模式与普通设计模式一样,只是用于设计和构建API的方法的蓝图。由于重点是接口而不是实现,在大多数情况下,API设计模式将专注于接口,而不一定会构建实现。虽然大多数API设计模式通常不会详细说明这些接口的底层实现,但有时它们会规定API行为的某些方面。例如,一个API设计模式可能会指定某个RPC可以是最终一致的(eventually consistent),这意味着从该RPC返回的数据可能会略有过时(例如,它可能会从缓存中读取而不是从存储系统中读取)。
在后面的章节中,我们将更详细地解释我们计划如何记录API模式,但首先让我们快速看看为什么我们应该关心API设计模式。
2.2 为什么API设计模式很重要
API设计模式之所以有用,类似于在建造小屋时使用设计图,是因为它们充当我们可以在项目中使用的预先设计的基本模块。然而,我们并没有深入探讨为什么我们需要这些预先设计的图纸。难道我们不足够聪明,可以构建出良好的API吗?难道我们不是最了解我们的业务和技术问题吗?虽然这通常是正确的,但事实是,当设计API时,我们用来构建非常精心设计的软件的一些技术在很大程度上无法奏效。特别是,敏捷开发过程特别推崇的迭代方法在设计API时很难应用。为了理解原因,我们必须探讨软件系统的两个方面。首先,我们必须研究各种接口的灵活性(或刚性),然后必须了解接口的受众对我们的变更和整体设计迭代产生的影响。让我们从灵活性(flexibility)开始。
正如我们在第1章中所看到的,API是一种特殊的接口,主要用于计算系统相互交互。尽管以编程方式访问系统非常有价值,但它也更加脆弱,因为接口的变更很容易导致使用接口的人发生故障。例如,在API中更改字段的名称将导致用户使用旧名称编写的代码发生故障。从API服务器的角度来看,旧代码正在使用一个不再存在的名称请求某个内容。这与其他类型的接口(例如图形用户界面(GUI))非常不同,后者主要由人类而不是计算机使用,因此更能够抵御变化。这意味着尽管变更可能令人不悦,但通常不会导致灾难性故障,使我们完全无法使用接口。例如,更改网页上按钮的颜色或位置可能会很丑陋和不方便,但我们仍然可以弄清楚如何使用接口来完成我们需要做的事情。
通常,我们将接口的这个方面称为其灵活性,即用户可以轻松适应变化的接口是灵活的,而即使是小的变更(例如重命名字段)也会导致完全失败的接口是刚性或死板(rigid)的。这个区别很重要,因为接口是否能够进行大量变化在很大程度上取决于接口的灵活性。最重要的是,我们可以看到刚性接口使我们难以像在其他软件项目中一样向完美的设计不断迭代。这意味着我们通常会被困在设计决策中,无论是好的还是坏的。这可能让你认为API的刚性意味着我们永远无法使用迭代式开发流程。但实际上情况并不总是这样,这要归功于接口的另一个重要方面:可见性(visibility)。
通常,我们可以将大多数接口分为两种不同的类别:用户可以看到和互动的接口(在软件中通常称为前端),以及他们无法看到的接口(通常称为后端)。例如,当我们打开浏览器时,可以轻松看到Facebook的图形用户界面;但是,我们无法看到Facebook如何存储我们的社交图和其他数据。为了对这个可见性方面使用更正式的术语,我们可以说前端(所有用户都可以看到和互动的部分)通常被认为是公共的(public),而后端(只对较小的内部人员组可见)被认为是私有的(private)。这个区别很重要,因为它在一定程度上决定了我们对不同种类的接口(特别是刚性的API)进行变更的能力。
如果我们对公共接口进行变更,整个世界都会看到它,并可能会受到它的影响。由于受众如此之大,粗心地进行变更可能会导致用户沮丧或愤怒。尽管这当然适用于刚性接口,比如API,但它同样适用于灵活的接口。例如,在Facebook的早期,大多数主要功能或设计变更都会在几周内引起大学生的愤怒。但是,如果接口不是公共的,对只有某个内部小组的成员可见的后端接口进行变更是否也很重要?在这种情况下,受变更影响的用户数量要小得多,甚至可能仅限于同一个团队或同一办公室的人员,因此似乎我们重新获得了更多自由来进行变更。这是个好消息,因为这意味着我们应该能够快速迭代朝着理想设计前进,同时应用敏捷原则。
那么,为什么API是特殊的呢?事实证明,当我们设计许多API(根据定义是刚性的)并与世界分享时,实际上存在两个方面(刚性和变更困难)的最坏情况。这意味着进行变更要比这两个属性的任何其他组合更加困难。
表2.2 接口变更的困难度
| 灵活性 | 受众 | 示例接口 | 变更困难度 |
|---|---|---|---|
| 灵活 | 私有 | 内部监控平台 | 非常容易 |
| 灵活 | 公共 | Facebook.com | 中等 |
| 死板 | 私有 | 内部存储API | 困难 |
| 死板 | 公共 | 公共Facebook API | 非常困难 |
简而言之,这种“两者兼具”的情况(既刚性又难以变更)使得可重复使用且经得起考验的设计模式对于构建API比其他类型的软件更为重要。在大多数软件项目中,代码通常是私有的,但API中的设计决策则是明显可见的,展示给服务的所有用户。由于这严重限制了我们对设计进行渐进性改进的能力,而依赖已经经受时间考验的现有模式会非常有价值——力争在第一次就做对事情而不是像在大多数软件中最终做对事情。
既然我们已经探讨了这些设计模式之所以重要的原因,让我们通过解构并探索它的各个组成部分来深入了解API设计模式。
2.3 解构API设计模式
像软件设计中的其他部分一样,API设计模式由几个不同的组件组成,每个组件负责处理模式的不同方面。显然,主要组件关注模式本身的工作原理,但还有其他一些组件针对设计模式的非技术性方面。这些组件包括如何确定某类问题存在某种与之对应的模式、了解模式是否适合你所处理的问题以及了解为什么模式采用的是某种方式而不是其他(可能更简单的)替代方法等等。
由于这个解构过程可能会变得有点复杂,让我们假设我们正在构建一个存储数据的服务,而该服务的客户希望拥有一个API,他们可以从服务中提取数据。我们将依赖这个示例场景来引导接下来要探讨的每个模式组件。首先我们从名称开始说起。
译者注: 此处提及的设计模式“组件”主要指的是本书在介绍每一种设计模式时遵循的固定流程,即按照“名称和摘要,动机,概述,接口实现,权衡“的顺序深入探讨每个模式。
2.3.1 名称和摘要
目录中的每个设计模式都有一个名称,用于在目录中唯一标识模式。名称应足够描述模式的功能,但不要冗长到拗口。例如,当描述解决我们的示例场景——数据导出的模式时,我们可以将其称为“导入、导出、备份、恢复、快照和回滚模式”,但更好的名称可能是“输入/输出模式”或简称为“IO模式”。
虽然名称本身通常足以理解和识别模式,但有时它可能不够详细,无法充分解释模式所解决的问题。为确保对模式本身有一个简短而简单的介绍,名称后面还会有一个模式的简要摘要,其中会简要描述它旨在解决的问题。例如,我们可以说输入/输出模式“提供了一种有序的方式,将数据从各种不同的存储源和目标位置移动。” 简而言之,本节的总体目标是使快速识别某个特定模式是否值得进一步研究,以确定是否适合解决特定问题。
2.3.2 动机
由于API设计模式的目标是为一类问题提供解决方案,因此最好在开头定义好模式旨在涵盖的问题领域。本节旨在解释基本问题,以便易于理解为什么我们需要这个模式。这意味着我们首先需要一个详细的问题陈述——通常以用户导向进行描述。在数据导出示例中,我们可能有一个场景,其中用户“想要将一些数据从服务中导出到另一个外部存储系统。”
之后,我们必须深入了解用户希望实现的目标细节。例如,我们可能会发现用户需要将其数据导出到各种存储系统,而不仅仅是Amazon的S3。他们还可能需要在传输之前对数据进行进一步约束,例如是否压缩或加密。这些要求将直接影响设计模式本身,因此重要的是我们要详细说明我们使用这个特定模式解决的问题细节。
接下来,一旦我们更全面地了解了用户目标,我们需要探索在实际实现的正常过程中可能出现的特殊情况。例如,我们应该了解当数据太大时系统应该如何反应(以及多大才算太大,因为这些词通常对不同的人有不同的含义)。我们还必须探讨系统遇到异常时应如何反应。例如,当导出作业失败时,我们应该描述是否应重试。这些不寻常的场景可能比我们通常期望的要常见得多,即使我们可能不必立即决定如何解决每个场景,但模式必须照顾到这些真空地带,以便最终可以由具体接口实现进行填补。
2.3.3 概述
现在我们越来越接近有趣的部分:解释设计模式建议的解决方案。在这一点上,我们不再专注于定义问题,而是提供解决方案的上层描述。这意味着我们可以开始探讨解决问题所需的策略和方法。例如,在我们的数据导出场景中,这一部分将概述各种组件及其职责,例如一个组件用于描述要导出的数据的详细信息,另一个组件用于描述作为导出数据目标位置的存储系统,还有一个组件用于描述在将数据发送到目标位置之前应用的加密和压缩设置。
在许多情况下,问题的定义和一系列需求将决定解决方案的一般大纲。在这些情况下,概述的目标是明确表述这个大纲,而不是让它从问题描述中被推断出来,无论解决方案多么明显。例如,如果我们正在定义一个用于搜索资源列表的模式,拥有一个查询参数似乎是相当明显的;但是,其他方面(例如该参数的格式或搜索的一致性保证)可能不那么明显,值得进一步讨论。毕竟,即使明显的解决方案也可能有微妙的影响,值得讨论,正如人们常说的,魔鬼通常隐藏在细节中。
另一方面,虽然问题已经定义得很好,但可能没有明显的单一解决方案,而是有多种不同的选项,每种选项都可能具有自己的利弊。例如,在API中建立多对多关系有许多不同的方法,每种方法都有其不同的优点和缺点;但是,重要的是API选择一种选项并一致地应用它。在这种情况下,概述将讨论每种不同的选项以及推荐模式所采用的策略。这一部分可能包含对提到的其他可能选项的优点和缺点的简要讨论,但更多的讨论将留到模式描述的最后的“权衡”部分。
2.3.4 接口实现
每个设计模式的最重要部分已经到来:我们如何实现它。此时,我们应该充分了解我们要解决的问题领域,并对上层策略和解决方法有所了解。这一部分最重要的内容将是以代码形式定义的接口,它解释了使用该模式来解决问题的API会是什么样子。API定义将关注资源的结构以及与这些资源进行各种具体交互的方式。这将包括各种内容,如资源或请求中定义的字段,可以进入这些字段的数据格式(例如Base64编码的字符串),以及资源之间的关系(例如层级关系)。
在许多情况下,API接口和字段定义本身可能无法解释API的实际工作原理。换句话说,虽然结构和字段列表可能看起来很清晰,但这些结构的行为和不同字段之间的交互可能复杂得多。在这些情况下,我们需要更详细地讨论这些并非显而易见的方面。例如,在导出数据时,我们可能会指定一种方法,在将数据传输到存储服务时使用字符串字段来指定压缩算法。在这种情况下,该模式可能会讨论该字段的各种可能值(可能使用与Accept-Encoding HTTP头使用的相同格式),当提供无效选项时应该执行什么操作(可能会返回错误),以及当请求留空该字段时的含义(可能会默认为gzip压缩)。
最后,这一部分将包括一个示例API定义,其中包含了注释来解释正确实现此模式的API应该是什么样的。这将以代码形式定义,其依赖于具体问题的示例场景,包含了解释各个字段行为的注释。这一部分几乎肯定会是最长且包含最多细节的部分。
2.3.5 权衡
到目前为止,我们了解了设计模式为我们提供了什么,但我们尚未讨论它带走了什么,实际上这也非常重要。坦白地说,如果严格按设计实现设计模式,可能有些事情是不可能的。在这些情况下,了解为了获得的好处而必须做出的牺牲非常重要。在这里可能会有各种可能性,从功能上的限制(例如,直接将数据作为Web浏览器中的下载提供给用户是不可能的)到增加的复杂性(例如,描述将数据发送到哪里需要更多的输入),甚至到更多的技术方面如数据一致性(例如,您可以看到数据可能有点陈旧,但不能确定)。因此这里的讨论可以既包括简单的解释,也包括在依赖特定设计模式时产生的微小缺陷。
此外,尽管某些设计模式通常适用于特定问题,但肯定会有一些情景,它虽然总体上符合要求,但却不完美。在这些情况下,了解依赖于这种设计模式将会产生什么后果非常重要:不是错误的模式,但也不是完美的模式。本节将讨论这种轻微不匹配的后果。
既然我们对API设计模式的结构和解释有了更好的了解,让我们换个角度看看在构建一个被认为是简单的API时,这些设计模式可以带来的差异。
2.4 案例研究: Twapi,一个类似Twitter的API
假设你不熟悉Twitter,可以将其看作是一个可以与他人分享短消息的地方——仅此而已。想到一个完整的业务建立在每个人创建微小消息的基础上有点吓人,但显然这足以使其成为一家价值数十亿美元的科技公司。这里没有提到的是,即使有一个非常简单的概念,在表面下实际上隐藏着相当多的复杂性。为了更好地理解这一点,让我们开始探讨Twitter可能的API是什么样子,我们将其称为Twapi。
2.4.1 概述
使用Twapi,我们的主要责任是允许人们发布新消息并查看其他人发布的消息。表面上看起来似乎很简单,但正如你可能猜到的,我们需要注意一些隐藏的陷阱。让我们首先假设我们有一个简单的API调用来创建Twapi消息。之后,我们将看一下此API可能需要的两个附加操作:列出消息和将所有消息导出到不同的存储系统。
在我们开始之前,有两件重要的事情需要考虑。首先,这将只是一个示例API。这意味着重点将放在我们如何定义接口上,而不是实现实际工作的方式。在编程术语中,这有点像说我们只会讨论函数定义,将函数体留待以后填充。其次,这将是我们首次尝试查看API定义。如果你还没有查看“关于本书”部分,现在是一个比较好的时机先阅读一遍,以便TypeScript样式的格式不会让你感到奇怪。
现在这些事情都澄清了,让我们看看如何列出Twapi消息。
2.4.2 消息列表
假设我们可以创建消息,那么很自然我们会希望列出创建的那些消息。此外,我们还想看到我们朋友创建的消息。更进一步,我们可能希望看到一个长列表,按照朋友消息的热门程度排序(有点像新闻推送)。让我们首先定义一个简单的API方法来实现这一点,不使用任何设计模式。
不使用设计模式
从头开始,我们需要发送一个请求,要求列出一堆消息。为此,我们需要知道我们想要的消息是谁的,我们将其称为“父级”(parent)。作为回应,我们希望我们的API返回一个简单的消息列表。该交互在图 2.1 中进行了概述。
图2.1 请求 Twapi 消息的简单流程
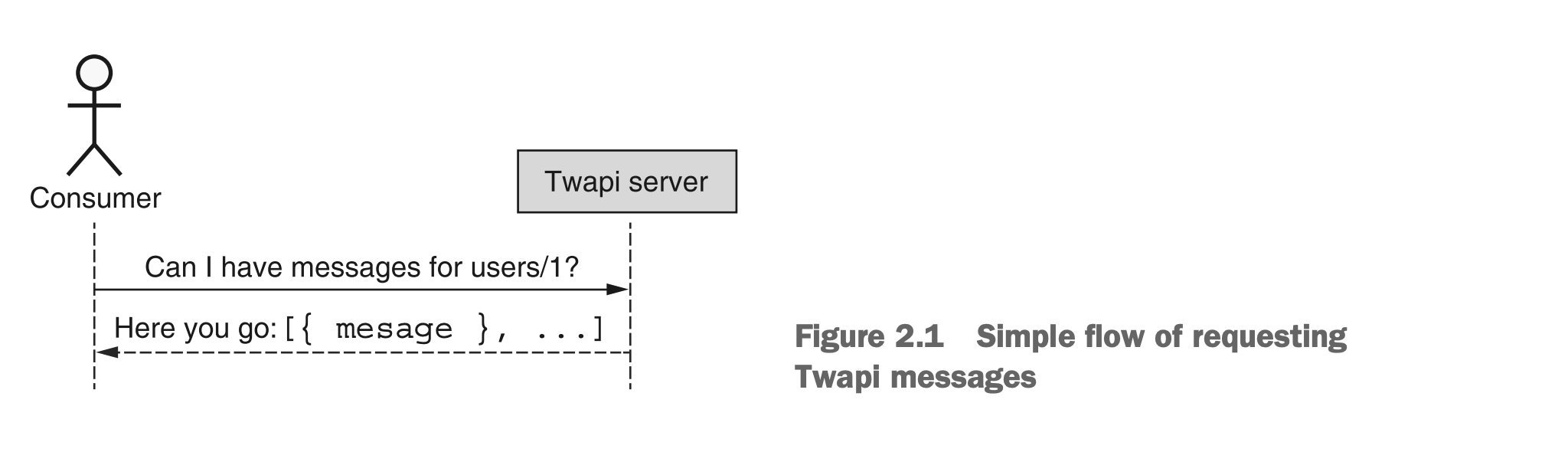
现在我们了解了列出这些消息涉及的流程,让我们将其正式化为一个真实的API定义。
代码2.1 列出Twapi消息的API示例
// 首先,我们将API服务定义为一个抽象类。这只是一组以TypeScript函数形式定义的API方法。
abstract class Twapi {
// 我们可以使用TypeScript的静态变量来存储关于API的元数据,比如名称或版本。
static version = "v1";
static title = "Twapi API";
// 在这里,我们依赖特殊的包装函数来定义HTTP方法(GET)和URL模式(/users/<user-id>/messages)
// 并将其映射到这个函数。
@get("/{parent=users/*}/messages")
// 这里`ListMessages` 函数接受一个 `ListMessagesRequest` 并返回一个 `ListMessagesResponse`。
ListMessages(req: ListMessagesRequest): ListMessagesResponse;
}
interface ListMessagesRequest {
// `ListMessagesRequest` 接受一个参数:`parent`。这是我们试图列出消息的所有者。
parent: string;
}
interface ListMessagesResponse {
// `ListMessagesResponse` 返回请求中提供的用户所拥有消息的简单列表。
results: Message[];
}
如您所见,这个API定义非常简单。它接受一个参数并返回匹配消息的列表。但让我们想象一下,假设我们将其部署为我们的API,并考虑随着时间推移可能出现的最大问题之一:数据量增加。
随着越来越多的人使用该服务,消息列表可能变得相当长。最初响应数十或数百条消息时,这可能并不是什么大问题。但是当您开始处理成千上万甚至百万条消息时呢?一个携带500,000条消息的单个HTTP响应,每条消息最多140个字符,意味着这可能高达70兆字节的数据!这对于常规的API用户来说似乎相当繁琐,更不用说一个单独的HTTP请求将导致Twapi数据库服务器发送70兆字节的数据。
那么我们该怎么办呢?明显, 答案是允许API将可能变得非常庞大的响应拆分成较小的部分,并允许用户一次请求全部消息中的一个片段。为此,我们可以依赖于分页模式(pagination pattern)(请参阅第26章)。
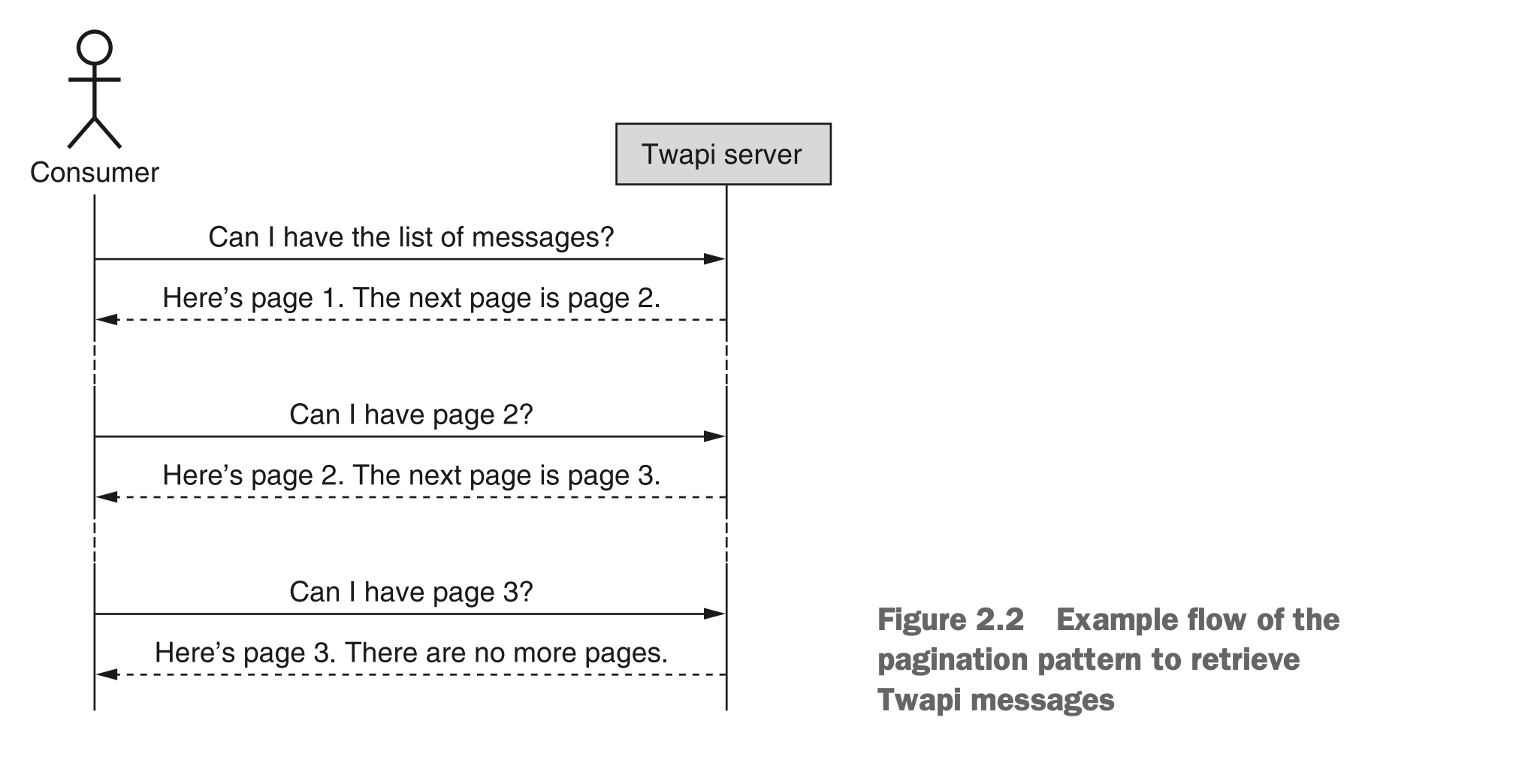
使用分页模式
正如我们将在第26章中了解到的那样,分页模式是以较小、更易管理的数据块的方式检索长列表项的一种方式,而不是一次性发送整个列表。该模式依赖于请求和响应上的额外字段;同时,这些字段应该看起来相当简单。该模式的一般流程如图 2.2 所示。
图2.2 检索Twapi消息的分页模式的示例流程
下面是实际的API定义示例。
代码2.2 列出带有分页的Twapi消息的示例API
abstract class Twapi {
static version = "v1";
static title = "Twapi API";
@get("/{parent=users/*}/messages")
// 注意,方法定义保持不变;这里不需要更改。
ListMessages(req: ListMessagesRequest): ListMessagesResponse;
}
interface ListMessagesRequest {
parent: string;
// 为了澄清我们正在请求哪个数据块(或页面),我们在请求中包含了一个页面令牌参数。
pageToken: string;
// 我们还使用一种方式来指定Twapi服务端在一个数据块中应该向我们返回消息的最大数量。
maxPageSize: number?;
}
interface ListMessagesResponse {
results: Message[];
// Twapi服务端的响应将包含一个令牌来获取下一块消息。
nextPageToken: string;
}
如果不从开始就使用分页模式会怎样
通过对API服务进行这些小的改变,我们实际上已经创建了一个能够在Twapi消息数量激增时保持稳定的API方法。但这留下了一个问题:为什么我要从一开始就遵循这种模式呢?为什么不等到问题出现时再添加这些字段呢?换句话说,为什么我们要费心去修复还没有出现的问题呢?正如我们将在后面讨论的向后兼容性(backward compatibility)中了解的那样,原因很简单,就是为了避免使现有软件出现问题。
在这种情况下,从我们更简单的原始设计(将所有数据在单个响应中返回)转向依赖分页模式(将数据分割成较小的块)可能看起来是一个无害的改变,但实际上它会导致任何之前存在的软件运行异常。在这种情况下,先前编写的代码会期望单个响应包含所有请求的数据,而不是其中的一部分,因此会出现了两个重要问题。
首先,由于先前编写的软件期望所有数据都在单个请求中返回,它无法找到出现在后续页面上的数据。因此,在变更之前编写的代码实际上无法获取除了第一个数据块之外的所有数据,这带来了第二个问题。
由于现有的使用者不知道如何获取附加的数据块,他们以为已经获得了所有数据,尽管实际上只有一小部分。这种误解可能导致非常难以检测的错误。例如,尝试计算某些数据的平均值的用户可能最终得到一个看起来正确但实际上只是第一个数据块的平均值的数值。显然,这可能导致一个不正确的值,但不会产生明显的系统异常。因此,这种错误可能会长时间存在而难以察觉。
现在我们已经看过列举消息的示例,接下来让我们探讨为什么在导出数据时也可能要使用设计模式。
2.4.3 导出数据
在某个时刻,Twapi服务的用户可能希望能够导出所有他们的消息。与列举消息类似,我们首先必须考虑到我们需要导出的数据量可能会变得相当大(可能达到数百兆字节)。此外,与列举消息不同,我们应该考虑到在接收端可能有许多不同的存储系统,并且理想情况下,我们应该有一种方法来与新兴存储系统集成。此外,我们可能希望在导出数据之前应用许多不同的转换,例如加密、压缩或根据需要对一些数据进行匿名处理。最后,所有这些都不太可能在同步方式下运行,这意味着我们需要一种方法,可以表示有待处理工作(即实际的数据导出)正在后台运行以供用户监视其进度。
让我们从为这个API制定一个简单的实现开始,然后看看未来可能出现的各种问题。
不使用设计模式
正如提到的,我们有一些主要关注点:大量数据、数据的最终目标位置、数据的各种转换或配置(例如,压缩或加密),以及API的异步性质。由于我们只是尝试为导出Twapi消息制定一个基本的API,最简单的选项是触发生成一个将来可供下载的压缩文件。简而言之,当有人发出对此API的请求时,响应实际上并不包含数据本身。相反,它包含一个指向将来某个可以下载数据的地址。
代码2.3 导出消息的简单API
abstract class Twapi {
static version = "v1";
static title = "Twapi API";
// 我们映射到的URI使用了POST HTTP动词,以及一种特殊的语法来表明这是执行的一项特殊操作,
// 而不是标准的REST操作之一。
@post("/{parent=users/*}/messages:export")
// 就像我们之前的例子一样,我们依赖于一个`ExportMessages`函数,该函数接受一个请求并返回一个响应。
ExportMessages(req: ExportMessagesRequest): ExportMessagesResponse;
}
interface ExportMessagesRequest {
// 我们只允许一次导出一个用户的数据,因此导出方法仅适用于单个父级(用户)。
parent: string;
}
interface ExportMessagesResponse {
// Twapi服务器的响应指定了以后可以从文件服务器下载的压缩文件的位置,而不是从此API服务下载。
exportDownloadUri: string;
}
这个API确实完成了主要任务(导出数据)和一些次要任务(异步检索),但缺少一些重要方面。首先,我们无法定义有关数据的额外配置的方法。例如,我们没有机会选择压缩格式或在加密数据时使用的密钥和算法。其次,我们无法选择数据的最终目标位置。相反,我们只是被告知以后可能查找它的位置。最后,如果我们更仔细地观察,就会清楚地看到接口的异步性质只是部分有用的:虽然服务确实以异步方式返回我们可以下载数据的位置,但我们无法监控导出操作的进度,也无法在不再对数据感兴趣的情况下中止操作。
让我们看看是否可以通过使用我们设计模式目录中稍后定义的一些设计模式来改进这个设计,主要集中在导入/导出模式上。
倒入/导出模式
正如我们将在第28章中学到的那样,导入/导出模式旨在解决类似于这样的问题:我们的API服务中有一些数据,用户希望有一种获取数据的方式(或将其导入)。然而,与我们之前讨论的分页模式不同,这个模式将依赖于其他模式,比如耗时操作模式(long-running operations)(在第13章中讨论)来完成任务。让我们首先定义API,然后更仔细地查看每个部分是如何协同工作的。就像以前一样,请记住我们不会详细讨论模式的每个方面,而是尝试提供相关部分的上层视图。
代码2.4 使用设计模式后的导出消息API
abstract class Twapi {
static version = "v1";
static title = "Twapi API";
@post("/{parent=users/*}/messages:export")
// 与先前的例子不同,我们的`ExportMessages`方法的返回类型是一个耗时操作,该操作在完成时返回一个`ExportMessagesResponse`,
// 并使用`ExportMessagesMetadata`接口报告有关操作的元数据。
ExportMessages(req: ExportMessagesRequest):
Operation<ExportMessagesResponse, ExportMessagesMetadata>;
}
interface ExportMessagesRequest {
parent: string;
// 除了`parent`(用户)之外,`ExportMessagesRequest`还接受有关生成的输出数据的一些额外配置。
outputConfig: MessageOutputConfig;
}
interface MessageOutputConfig {
// 在这里,我们定义了“destination”(目标位置),它表示操作完成时数据应该到达的位置。
destination: Destination;
// 此外,我们可以使用单独的配置对象调整数据的压缩或加密方式。
compressionConfig?: CompressionConfig;
encryptionConfig?: EncryptionConfig;
}
interface ExportMessagesResponse {
// 结果将回显用于将数据输出到结果目标时使用的配置。
outputConfig: MessageOutputConfig;
}
interface ExportMessagesMetadata {
// `ExportMessagesMetadata`将包含有关操作的信息,如进度(以百分比表示)。
progressPercent: number;
}
这个模式有什么好处呢?首先,通过依赖封装的输出配置接口,我们能够在请求时接受各种参数,然后在响应中将相同的内容作为确认返回给用户。接下来,在这个配置中,我们能够定义几个不同的配置选项,我们将在代码2.5中更详细地讨论。最后,我们能够使用耗时操作的元数据信息来跟踪导出操作的进度,该信息存储操作的进度百分比(0%表示“未启动”,100%表示“完成”)。
话虽如此,您可能已经注意到我们在先前的API定义中使用的一些模块未被定义。现在让我们明确定义它们并提供一些示例配置。
代码2.5 用于配置目标位置和设置的接口
interface Destination {
typeId: string;
}
// 就像最初的例子一样,我们可以定义一个文件目标位置,将输出放在文件服务器上,以便以后下载。
interface FileDestination extends Destination {
fileName: string;
}
// 除了文件下载的例子,我们还可以要求将数据存储在亚马逊的S3上的某个位置。
interface AmazonS3Destination extends Destination {
uriPrefix: string;
}
interface CompressionConfig {
typeId: string;
}
// 在这里,我们定义了其他压缩选项以及每个选项的配置值。
interface GzipCompressionConfig {
// An integer value between 1 and 9.
compressionLevel: number;
}
// 我们可以在单个接口中定义所有加密配置选项,
// 也可以使用相同的子类结构(如压缩配置所示)来表示各种选择。
interface EncryptionConfig {
...
}
这里我们可以看到定义配置选项的各种方式,比如数据的目标位置或数据应该如何进行压缩。唯一剩下的就是要了解这个耗时操作到底是如何工作的。我们将在第28章中更详细地探讨这个模式,但现在,让我们简单地提出这些接口的API定义,以便至少对它们在做什么有一个总体理解。
代码2.6 通用错误接口和耗时操作接口的定义
// 一个必须的基本组件是错误的定义,它至少包括错误代码和消息。
// 还可以包括一个可选字段,其中包含有关错误的更多详细信息。
interface OperationError {
code: string;
message: string;
details?: any;
}
// 耗时操作是一种类似于`Promise`的结构,基于结果和元数据类型进行参数化(就像C++/Java泛型)。
interface Operation<ResultT, MetadataT> {
id: string;
done: boolean;
result?: ResultT | OperationError;
metadata?: MetadataT;
}
如果不从开始就使用这些设计模式会怎样
前例(分页模式示例)中受模式驱动和非模式驱动的选项看起来相似,而本例(导出模式示例)却不同,这两个选项在最终的API上有显著差异。因此,对于这个问题的答案是明确的:如果您发现自己需要提供某些功能(不同的导出目标位置、单独的配置等),那么从非模式驱动的方法开始将导致对用户的破坏性变更。而通过从起始点采用模式驱动的方法,API将在需要新功能时得到优雅的演进。
本章总结
- API设计模式有点像用于设计和构建API的可调试蓝图。
- API设计模式之所以重要,是因为API通常非常“刚性”,因此不容易更改,设计模式有助于最小化对大型结构变更的需求。
- 在本书中,API设计模式将包括几个部分,包括名称和摘要、建议的规则、动机、概述、接口实现以及使用提供的模式而非其他替代方案的权衡。
概述
我们API设计工具箱中并非所有工具都是设计模式。在接下来的几章中,我们将研究一些在API设计中不太符合设计模式(如第2章定义)的主题,但它们仍然对我们构建良好API非常重要(如第1章定义)。
在第3章中,我们将探讨为API的不同组件命名的准则。接下来,在第4章中,我们将介绍如何在逻辑上安排这些组件并定义它们之间的关系。最后,在第5章中,我们将看看在API中定义不同字段时,如何在众多数据类型之间进行决策。
第三章 命名
本章涵盖:
- 为什么我们应该关心命名
- 如何使命名更合理
- 如何在语言、语法和句法方面做出选择
- 上下文如何影响名称的含义
- 糟糕命名的案例研究
不管我们是否喜欢,名称无处不在。在我们构建的每个软件系统和设计或使用的每个API中,都有名称潜伏在每个角落,它们将存在比我们预计更长的时间。因此,选择好的名称是重要的(尽管我们并不总是认真考虑我们的命名选择)。在本章中,我们将探讨API的不同组件的命名,一些选择良好名称的策略,将好名称与差名称区分开的高级属性,以及在不可避免地做出困难的命名决策时指导我们的一些一般原则。
3.1 为什么名称很重要
在软件工程的世界中,几乎不可能避免为事物选择名称。即便我们只需要编写使用语言关键字(例如class,for或if)的代码块,这在最好的情况下也是难以阅读的。考虑到这一点,编译软件是一个特例。这是因为在传统的编译代码中,我们的函数和变量的名称只对那些可以访问源代码的人是有意义的,因为名称本身通常在编译(或压缩)和部署过程中消失。
另一方面,当设计和构建API时,我们选择的名称更加重要,因为它们是API的所有用户将看到和与之交互的内容。换句话说,这些名称不会简单地被编译隐藏,而是对外可见。这意味着我们需要对我们为API选择的名称进行非常多的思考。
显而易见的问题是:“如果发现糟糕的命名,我们不能更改名称吗?”正如我们将在第24章中学到的,更改API中的名称可能非常具有挑战性。想象一下更改源代码中频繁使用的函数的名称,然后意识到您需要进行大量的查找和替换,以确保您更新了对该函数名称的所有引用。尽管这可能有点不方便(在某些IDE中可以很容易),但这当然是可能的。但是,请考虑如果此源代码可供公众构建到其自己的项目中。即使您可以以某种方式更新所有公共源代码的所有引用,始终会有您无法访问并且因此无法更新的私有源代码。
换句话说,在API中更改面向公众的名称有点像更改您的地址或电话号码。要成功地在所有地方更改此数字,您必须与曾经拥有您电话号码的每个人联系,包括使用纸质地址簿的祖母和曾经访问它的每个营销公司。即使您有一种方法与拥有您号码的每个人联系,您仍然需要他们做更新联系信息的工作,而这可能是他们太忙无法完成的工作。
既然我们已经看到选择好的名称(并避免更改它们)的重要性,这引出了一个重要的问题:什么是一个“好”名称呢?
3.2 什么是“好”的名称
正如我们在第1章中学到的那样,好的API需要表达能力强,简单且可预测。而名称则非常相似,只是它们不一定是“可操作的”(换句话说,名称实际上并不执行任何操作)。让我们分别看看这些属性以及一些命名选择的示例。首先是表达性。
3.2.1 表达性
比任何其他方面都重要的是,名称必须清晰地传达其命名的事物。这个事物可能是一个函数或RPC(例如,CreateAccount),一个资源或消息(例如,WeatherReading),一个字段或属性(例如,postal_address),或者完全不同的东西,比如一个枚举值(例如,Color.BLUE),但读者应该清楚地知道这个事物代表着什么。这可能听起来很容易,但是对于不了解在特定领域中上下文的人,就显得比较困难了。这种上下文通常是一个巨大的优势,但在这种情况下更像是一种负担:它使我们在命名事物时表现糟糕。
例如,术语“topic”在异步消息传递的上下文中经常被使用(例如,Apache Kafka或RabbitMQ);然而,它在机器学习和自然语言处理的一个特定领域中也被使用(topic modeling)。如果你在你的机器学习API中使用术语“topic”,用户可能会对你指的是哪一种类型的主题(topic)感到困惑,这并不奇怪。如果这是一个真实的用例(也许你的API既使用异步消息传递,又使用主题建模),你可能希望选择一个比“topic”更有表达力的名称,比如“model_topic”或“messaging_topic”,以防止用户混淆。
3.2.2 简洁性
虽然有表达力的名称当然很重要,但如果名称过长而没有增加额外的清晰度,它也可能变得繁琐。使用之前的例子(“topic”在计算机科学的多个不同领域中使用),如果一个API只涉及异步消息传递(例如,类似于Apache Kafka的API),与机器学习无关,那么“topic”已经足够清晰和简单,而“messaging_topic”就不会增加太多价值。简而言之,名称应该具有表达力,但只有在名称的每个附加部分都增加了价值以证明其存在的合理性时才能具有表达力。
另一方面,名称也不应过于简化。例如,想象一下我们有一个需要存储一些用户指定偏好的API。资源可能被称为“UserSpecifiedPreferences”;然而,“Specified”并没有为名称增添太多内涵。另一方面,如果我们简单地将资源命名为“Preferences”,那么这是不清楚是谁的偏好,并且在以后需要存储和管理系统或管理员级偏好时可能会引起混淆。在这种情况下,“UserPreferences”似乎是具有表达力和简单之间的平衡点,总结在表3.1中。
表3.1 在表达性和简洁性之间选择
| 名称 | 说明 |
|---|---|
UserSpecifiedPreferences | 具有表达力,但不够简洁 |
UserPreferences | 简洁,并有足够的表达性 |
Preferences | 过于简洁 |
3.2.3 可预测性
现在我们已经讨论了表达性和简洁性之间的平衡,还有一个非常重要的方面:可预测性。想象一个API使用名称“topic”将类似的异步消息组合在一起(类似于Apache Kafka)。然后该API在其他地方使用名称“messaging_topic”而不是“topic”,这将导致一些非常令人沮丧和不寻常的情况。
代码3.1 不一致的命名示例
function handleMessage(message: Message) {
// 这里我们使用`topic`读取给定消息的主题
if (message.topic == "budget.purge") {
client.PurgeTopic({
// 这里我们使用了`messagingTopic`来表示相同的概念
messagingTopic: "budget.update"
});
}
}
在这种情况下,且不考虑是否会导致用户困扰,请考虑我们可能违反的一个重要原则。通常情况下,我们应该使用相同的名称表示相同的事物,使用不同的名称表示不同的事物。如果我们将这个原则看作是公理,这就引出了一个重要的问题:“topic”与“messagingTopic”有何不同?毕竟,我们使用了不同的名称,所以它们必须代表不同的概念,对吧?
通常一个基本的目标是允许API的用户学习一个名称,并继续在此基础上构建知识,以便能够预测未来的名称(例如,如果它们代表相同的概念)会是什么样子。通过在API中一致使用“topic”来表示“给定消息的主题”(以及在表示不同概念时使用其他名称),我们允许API的用户基于他们已经学到的知识去构建应用,而不是混淆这些名称,并迫使用户研究每个名称以确保它的含义与他们的假设相符。
现在我们对好的名称的一些特征有了了解,让我们继续探讨在API中命名事物时可以作为防护栏的一般指导原则。首先从语言、语法和句法开始。
3.3 语言,语法与句法
虽然代码的本质是二进制,基本上存储为数字,但命名是一个我们使用语言来表达的主观构造。与编程语言不同,编程语言对于什么是有效的和什么是无效的有非常明确的规则,而语言的演变更多地服务于人类,使规则变得不太明确。这使得我们的命名选择变得更加灵活和模糊,这既是一件好事也是一件坏事。
一方面,模糊性使我们能够命名事物以足够普遍的方式来支持未来的工作。例如,将字段命名为image_uri而不是jpeg_uri,可以防止我们限制自己只能使用单一的图像格式(JPEG)。另一方面,当有多种表达相同事物的方式时,我们通常倾向于互换使用它们,这最终使我们的命名选择变得不可预测(参见第3.2.3节),并导致API变得令人沮丧和繁琐。为了避免其中一些问题,即使“语言”具有相当大的灵活性,通过强加一些我们自己的规则,我们可以避免失去对于一个良好的API非常重要的可预测性。在本节中,我们将探讨与语言相关的一些简单规则,这些规则有助于在为事物命名时减少一些我们不得不做出的武断选择。
3.3.1 语言
虽然世界上有许多语言,但如果我们不得不选择一种在软件工程中使用最广泛的语言,目前美式英语是最有竞争力的选择。这并不是说美式英语比其他语言更好或更差;只是如果我们的目标是在全球范围内实现最大的互操作性,使用美式英语以外的任何语言都可能成为阻碍而不是帮助。
这意味着应该使用英语语言概念(例如,使用BookStore而不是Librería),并且通常应优先选择常见的美式拼写(例如,color而不是colour)。这还有一个额外的好处,就是可以很好地适应ASCII字符集。只有在美式英语从其他语言中借用了一些词汇的情况下才有一些例外(例如,café)。
这并不意味着API的注释必须使用美式英语。如果API的受众群体完全位于法国,提供法语文档可能是有意义的。然而,使用API的软件工程师团队可能会使用其他API,这些API不太可能专门面向法国的客户。因此,即使API的受众群体不使用美式英语作为他们的主要语言,API本身仍应依赖于美式英语作为所有使用大量不同API的各方之间的共享通用语言。
3.3.2 语法
鉴于API将使用美式英语作为标准语言,这会引发一些复杂的问题,因为英语并不是最简单的语言,有许多不同的时态和语气。幸运的是,发音不是问题,因为源代码是一种书面语言,而不是口语语言,但这并不一定消除了所有潜在的问题。
与其试图规定美式英语语法在API中命名事物的每一个方面,不如简要介绍一下最常见的一些问题。让我们首先看看行为类词语(例如,RPC方法或RESTful动词)。
祈使动词
在任何API中,都会存在类似于编程语言“函数”的东西,这些函数执行API期望的实际工作。这可能是一个纯粹的RESTful API,仅依赖于特定的预设操作列表(Get、Create、Delete等),那么在这里你没有太多事情要做,因为所有操作都将采用<标准动词><名词>的形式(例如,CreateBook)。在允许非标准动词的非RESTful或面向资源的API中,我们有更多选择来命名这些操作。
REST标准动词有一个共同的重要方面:它们都使用祈使语气。换句话说,它们都是动词的命令或指令。如果这听起来有点费解,请想象一下军队中的教官对你大喊要你做某事:“创建那本书!”“删除那个天气记录!”“存档那个日志条目!”尽管这些命令对军队来说有点荒谬,但你确切地知道你应该做什么。
另一方面,有时我们编写的函数的名称可能采用陈述语气。一个常见的例子是当一个函数正在调查某事时,例如C#中的String.IsNullOrEmpty()。在这种情况下,“to be”动词采用了陈述语气(询问有关资源的问题),而不是祈使语气(命令服务执行某些操作)。
虽然函数采用这种语气基本上没有什么问题,但在Web API中使用时会留下一些重要的问题。首先,对于看起来可以在不询问远程服务的情况下处理的事情,“isValid()实际上是否会导致远程调用,还是在本地处理?”虽然我们希望用户认为所有方法调用都经过网络,但这种外观上类似于无状态调用,而实际上经过网络调用会有点误导用户。
其次,响应应该是什么样的?以一个名为isValid()的RPC为例。它应该返回一个简单的布尔字段,说明输入是否有效吗?如果输入无效,它应该返回一个错误列表吗?另一方面,GetValidationErrors()更清晰:如果输入完全有效,它将返回一个空列表,如果输入无效,则返回一个错误列表。关于响应的形式没有任何的困惑。
介词
在选择名称时,另一个令人困惑的领域涉及介词,如“with”、“to”或“for”。尽管这些词在日常对话中非常有用,但在Web API的上下文中,特别是在资源名称中使用时,它们可能暗示API存在更复杂的基本问题。
例如,一个图书馆API可能有一种列出图书资源的方法。如果这个API需要一种方法来列出图书资源并包含负责该书的作者资源,可能会忍不住为此组合创建一个新资源:BookWithAuthor(然后通过调用ListBooksWithAuthors或类似的方法进行列出)。乍一看,这似乎没问题。但是当我们需要列出嵌入了Publisher资源的Book资源时呢?或者同时包含Author和Publisher资源?在我们意识到之前,我们将有30个不同的RPC需要调用,这取决于我们想要的不同相关资源组合。
在这种情况下,我们想在名称中使用的介词(“with”)表明了一个更基本的问题:我们希望一种方法来列出资源并在响应中包含不同的属性。我们可能会使用字段掩码(field mask)或视图(view)(见第8章)来解决这个问题,同时避免使用这个奇怪的名称。在这种情况下,介词是一个指示,有时表明了一些并不太对劲的迹象。因此,即使介词可能不应完全被禁止(例如,可能会将字段称为bits_per_second),但这些棘手的小词就像代码异味一样,暗示着某些地方不太对劲,值得进一步调查。
复数
在API中,我们通常会选择事物的名称采用单数形式,例如Book、Publisher和Author(而不是Books、Publishers或Authors)。此外,这些名称往往在API中被赋予新的含义和用途。例如,Book资源可能会在某个地方被一个名为Author.favoriteBook的字段引用(参见第13章)。然而,当我们需要谈论这些资源的多个实例时,情况有时会变得混乱。使事情变得更加复杂的是,如果API使用RESTful URL,一堆资源的集合名称几乎总是复数形式。例如,当我们请求单个Book资源时,URL中的集合名称几乎肯定是类似/books/1234的形式。
对于我们用作示例的名称(例如Book),这并不是什么大问题;毕竟,提到多个Book资源只需要在名称后添加一个“s”即可将其变为复数形式Books。然而,有些名称并不那么简单。例如,想象一下我们正在为足科医生办公室制作一个API。当我们有一个Foot资源时,我们需要打破只需添加“s”的模式,从而形成一个feet集合。
这个例子确实打破了模式,但至少它是清晰而明确的。如果我们的API涉及人员,因此有一个Person资源,那么集合是persons还是people呢?换句话说,应该通过类似/persons/1234还是/people/1234的URL来检索Person(id=1234)?幸运的是,我们关于使用美式英语的指南规定了一个答案:使用people。
其他情况可能令人更加沮丧。例如,想象一下我们正在为水族馆制作一个API。章鱼资源的集合是什么呢(译者注:octopus的复数形式可以是octopuses或octopi或octopodes)?正如你所看到的,我们选择美式英语有时会让我们后悔。然而,最重要的是我们选择一种模式并坚持下去,这通常涉及迅速查找语法学家认为正确的答案(在这种情况下,“octopuses”是完全可以接受的)。这也意味着我们永远不应该假设资源的复数形式可以通过简单添加“s”来创建,这是软件工程师寻找模式时常见的诱惑。
3.3.3 句法
现在我们进入了命名更为技术性的方面。与我们之前看到的其他方面一样,当涉及到句法时同样的准则也适用。首先,选择一种方式并坚持下去。其次,如果有现有的标准(例如,美式英语拼写),就使用该标准。那么在实际情况下这意味着什么呢?让我们从大小写开始。
大小写
在定义API时,我们需要为各种组件命名,这些组件包括资源、RPC和字段等。对于这些组件,我们往往使用不同的命名规范,这有点像一种用于渲染名称的格式。通常,这种渲染仅在如何将多个单词串在一起形成单个词法单元方面显现出来。例如,如果我们有一个表示名字的字段,我们可能需要将该字段命名为“first name”。然而,在几乎所有编程语言中,空格是词法分隔符,因此我们需要将“first name”合并为一个单元,这为很多不同的选项打开了大门,比如“驼峰命名法”、“蛇形命名法”或“烤肉串命名法”。
在驼峰命名法中,单词通过将第一个单词之后的所有单词首字母大写后进行拼接,因此“first name”将呈现为firstName(就像骆驼一样有大写字母作为驼峰)。在蛇形命名法中,单词使用下划线字符连接,如first_name(看起来有点像蛇)。在烤肉串命名法中,单词使用连字符连接,如first-name(看起来有点像串在一起的烤肉串)。根据用于表示API规范的编程语言不同,不同的组件以不同的命名规范呈现。例如,在Google的Protocol Buffer语言中,消息(message)(类似于TypeScript接口)的标准是使用大驼峰命名法,如UserSettings(请注意大写的“U”),字段名称使用蛇形命名法,如first_name。另一方面,在OpenAPI规范中,字段名称采用驼峰命名法,如firstName。
正如前面提到的,具体的选择并不是那么重要,只要在整个API中一致使用这些选择。例如,如果你在Protocol Buffer 消息中使用名称user_settings,很容易认为这实际上是一个字段名称而不是消息。因此,这很可能会让使用API的人感到困惑。说到类型,让我们简要地看一下保留字段。
保留关键字
在大多数API定义语言中,会有一种方式来指定存储在特定属性中的数据的类型。例如,我们可以用firstName: string,以在TypeScript中表示名为firstName的字段包含原始字符串值。这也意味着术语string在不同位置的代码中具有某种特殊含义。因此,在API中使用受限制的关键字作为名称可能是危险的,应尽量避免。
如果感到很困难,花一些时间思考字段或消息真正代表的内容,而不是选择最容易的选项。例如,与其使用“to”和“from”(在诸如Python之类的语言中是那些特殊的保留关键字),你可能想尝试使用更具体的术语,如“sender”和“recipient”(如果API涉及消息),或者“payer”和“payee”(如果API涉及支付)。
考虑API的目标受众也很重要。例如,如果API只会在JavaScript中使用(也许它被设计为仅在Web浏览器中使用),那么其他语言(例如Python或Ruby)中的关键字可能不值得担心。尽管如此,如果不费力,最好还是避免其他语言中的关键字。毕竟,你永远不知道你的API何时可能会被哪一种语言使用。
既然我们已经讨论了一些技术方面的内容,让我们跳到更高的层次,谈谈我们的API所处和所运作的上下文如何影响我们对名称的选择。
3.4 上下文
虽然单独的名称有时可能足以传达所有必要的信息以便发挥作用,但更多时候我们依赖于名称的使用上下文来辨别其含义和预期用途。例如,在API中使用术语"book"时,我们可能指的是存在于Library API中的资源;然而,我们也可能指的是在Flight Reservation API中执行的操作。正如你可以想象的,相同的词语和术语在不同的上下文中可能有完全不同的含义。这意味着在选择API名称时,我们需要牢记API所处的上下文。
重要的是要记住,这是双向的。一方面,上下文可以为一个名称赋予额外的价值,否则该名称可能缺乏具体含义。另一方面,当我们使用具有非常具体含义但在给定上下文中并不太合适的名称时,上下文可能会误导我们。例如,"record"这个名字如果没有附近的上下文可能不太有用,但在音频记录API的上下文中,这个术语会被API的一般上下文赋予额外含义。
简而言之,虽然在给定上下文中如何命名事物没有严格的规则,但要记住的重要事情是我们在API中选择的所有名称与该API提供的上下文紧密相连。因此,在选择名称时,我们应该意识到上下文以及它在选择名称时可能赋予的含义(无论是好是坏)。
让我们稍微改变方向,谈谈数据类型和单位,特别是它们如何影响我们选择名称。
3.5 数据类型和单位
尽管许多字段名称在没有单位的情况下就具有描述性(例如,firstName: string),但其他一些字段如果没有单位可能会非常令人困惑。例如,想象一个名为“size”的字段。根据上下文(参见第3.4节),这个字段可能有完全不同的含义,也可能有完全不同的单位。我们可以看到相同的字段(size)在不同情境下可能具有完全不同,而且在许多情况下可能令人困惑的含义和单位。
代码3.2 不同接口使用相同字段
// size字段的单位令人困惑。它是以字节为单位的大小吗?
// 还是音频的持续时间(以秒为单位)?或者是图像的尺寸?还是其他什么?
interface AudioClip {
content: string;
size: number;
}
interface Image {
content: string;
size: number;
}
在这个例子中,size字段可能有多重含义,但这些不同的含义也将导致非常不同的单位(例如,字节、秒、像素等)。幸运的是,这种关系是双向的,这意味着如果单位出现在某个地方,含义将变得更清晰。换句话说,sizeBytes和sizeMegapixels比仅使用size更为清晰和明显。
代码3.3 通过加入单位信息使字段名称更清晰
// 通过加入单位信息使size字段名称更清晰
interface AudioClip {
content: string;
sizeBytes: number;
}
interface Image {
content: string;
sizeMegapixels: number;
}
这是否意味着我们在所有情况下都应该简单地包含任何给定字段的单位或格式?毕竟,在像上面展示的情况中,这肯定会有利于避免任何混淆。例如,想象一下,我们想要在像素资源中存储图像的尺寸以及字节大小。我们可能有两个字段,分别称为sizeBytes和dimensionsPixels。但尺寸实际上有两个数字:我们需要长度和宽度。一种选择是使用字符串字段,并以某种常见的格式提供尺寸。
代码3.4 使用字符串字段存储以像素为单位的图像尺寸
interface Image {
content: string;
sizeBytes: number;
// 字段的格式在字段本身的前导注释中说明。
// 字段的单位是明确的(像素),但基本数据类型(string)可能令人困惑。
// The dimensions (in pixels). E.g., "1024x768".
dimensionsPixels: string;
}
尽管这个选项在技术上是有效的,并且当然是清晰的,但它显示了一种过于追求始终使用基本数据类型的倾向,即使在某些情况下这样做可能并不合理。换句话说,就像有时在名称中包含单位使名称变得更清晰和可用一样,其他时候在使用更丰富的数据类型时名称可能变得更清晰。在这种情况下,我们可以使用一个Dimensions接口,其中包含长度和宽度的数值,其中名称中包含了单位(像素)。
代码3.5 依赖于更丰富数据类型来表示图像尺寸
interface Image {
content: string;
sizeBytes: number;
// 在这种情况下,维度字段的名称无需在名称中包含单位,因为更丰富的数据类型传达了含义。
dimensions: Dimensions;
}
interface Dimensions {
// 该字段的单位清晰可见(像素),无需任何特殊的字符串格式。
lengthPixels: number;
widthPixels: number;
}
在这种情况下,"dimensions" 字段的含义清晰明了。而且,我们不必解包(unpack)字段本身的一些特殊结构细节,因为 "Dimensions" 接口已经为我们完成了这个任务。让我们通过一些案例研究总结一下,在选择API中的名称时如果没有采取适当的预防措施会出现哪些问题。
3.6 糟糕命名的案例研究
关于如何选择好的名称,以及在选择过程中需要考虑的方面看上去已经很清楚,但通过一些真实世界的例子来看一下那些不太恰当的命名依然是值得的。此外,我们还可以看到这些命名选择的最终后果以及它们可能引起的潜在问题。让我们首先看一个命名问题,其遗漏了一个微小但重要的部分。
微小的含义(subtle meaning)
如果你走进一家Krispy Kreme的面包房要10个甜甜圈,你期望得到10个甜甜圈,对吧?如果你只得到了8个甜甜圈,你可能会感到惊讶吧?也许如果你只拿到了8个甜甜圈,你会认为这家店肯定已经卖光了甜甜圈。如果说必须先要8个,之后再要求2个才能得到你想要的10个,你一定不会觉得这是个合理的过程。
但是,如果你一次只能要求最多N个甜甜圈呢?换句话说,你只能问收银员:“我能要最多10个甜甜圈吗?”你会得到任意数量的甜甜圈,但永远不会超过10个。(请记住,这可能导致你一个甜甜圈也得不到!)突然间,上一个甜甜圈店的奇怪行为有了解释。尽管这很不方便(我还没有见过一家采用这种订购系统的甜甜圈店),但至少不是令人困惑和惊讶的。
在第21章,我们将学习一个设计模式,演示如何在List标准方法操作中分页浏览大量资源,这种方式既安全又清晰,并且可以很好地适应大量资源。结果发现,仅能要求最大值(而不是确切数量)正是分页模式的工作原理(使用maxPageSize字段)。
Google的工程师们(出于历史原因)遵循了描述的分页模式,但有一个重要的区别:request请求不是指定maxPageSize,而是指定pageSize以表示“给我最多N个条目”。这三个缺失的字符(max)导致了极大的混淆,就像点甜甜圈的人一样:他们认为他们正在要求确切的数量,但实际上他们只能要求最大数量。
最常见的情况是有人要求10个项目,却只得到8个,并认为可能没有更多项目了(就像我们可能会认为甜甜圈店的甜甜圈已经卖完了)。实际上,情况并非如此:仅因为我们得到了8个并不意味着店里没有了甜甜圈;这只是意味着他们需要到后面去找更多。这最终导致API用户错过了许多项目,因为他们在实际列表结束之前停止了对结果进行分页浏览。
虽然这可能令人沮丧并导致一些不便,但让我们看一下由于混淆字段的单位而导致的一个更为严重的错误。
单位
时间回到1999年,NASA计划将火星气候轨道器调整到离表面约140英里的轨道。他们进行了大量计算,以确定应用的动力,以使轨道器达到正确的位置,然后执行了这次行动。不幸的是,很快团队注意到轨道器并没有到达它应该在的位置。它并没有在距离表面140英里的地方,而是低得多。实际上,后来的计算似乎显示轨道器距离表面仅有35英里。遗憾的是,轨道器能够生存的最低高度是50英里。正如你所预料的那样,低于这个高度意味着轨道器很可能在火星大气中被摧毁。
在随后的调查中,发现Lockheed Martin团队使用的是美制单位(具体而言是lbf-s或磅力秒),而NASA团队使用的是国际单位制(具体而言是N-s或牛顿秒)。一个快速的计算显示1磅力秒等于4.45牛顿秒,这最终导致轨道器获得了超过所需冲动力四倍以上的量,最终使其降至最低高度以下。
代码3.6 MCO计算API的简化示例
abstract class MarsClimateOrbiter {
CalculateImpulse(CalculateImpulseRequest): CalculateImpulseResponse;
CalculateManeuver(CalculateManeuverRequest): CalculateManeuverResponse;
}
interface CalculateImpulseResponse {
// 这里计算了脉冲,但没有提供单位!
// 这通常意味着我们可以将该输出作为下面`CalculateManeuverRequest`的输入。
impulse: number;
}
interface CalculateManeuverRequest {
impulse: number;
}
如果集成点在字段名称中包含了单位,错误就会显而易见。
代码3.7 如果在接口字段中包含了单位
// 这里显而易见,由于单位不同,你不能简单地将一个API方法的输出直接输入到下一个方法中。
interface CalculateImpulseResponse {
impulsePoundForceSeconds: number;
}
interface CalculateManeuverRequest {
impulseNewtonSeconds: number;
}
显然,火星气候轨道器比这里所描绘的要复杂得多,而且很可能无法仅仅通过使用更具描述性的名称就避免这种情况(事件详细信息)。尽管如此,这个例子很好地说明了为什么描述性的名称是有价值的。它可以帮助突显差异,特别是在不同团队之间进行协调时。
3.7 练习
-
想象一下你需要创建一个用于管理重复日程的API(“例如此事件每月发生一次”)。一位资深工程师认为,仅存储事件间隔的秒数对所有用例来说已经足够。另一位工程师认为API应该提供不同的字段,表示各种时间单位(例如,秒、分钟、小时、天、周、月、年)。哪种设计更好地涵盖了预期功能的正确含义,从而是更好的选择?
-
在你的公司,存储系统使用千兆字节作为测量单位(10^9 bytes)。例如,创建共享文件夹时,你可以通过设置
sizeGB = 10来将大小设置为10GB。现在推出了一个新的API,其中网络吞吐量以吉比特(2^30 bits)为单位,并希望以吉比特为单位设置带宽限制(例如,bandwidthLimitGib = 1)。这个差异是否太过微妙从而可能会令用户感到困惑?为什么?
本章总结
以下要点总结了本章讨论的原则:
- 简洁性、表达性和可预测性:良好的名称,就像良好的API一样,应该简洁、富有表达力且可预测。
- 语言和语法的一致性:在语言、语法和其他任意方面,通常最好选择一种标准并始终保持一致。
- 名字中的介词可能是设计问题的信号:名字中的介词可能表明存在一些需要解决的潜在设计问题。
- 上下文感知:名称从使用它们的上下文中获得意义。在选择名称时,考虑更广泛的上下文至关重要。
- 在名称中包含单位,使用丰富的数据类型:在原始数据类型中包含单位并利用更丰富的数据类型可以增强名称的清晰度,传达额外的信息。
这些原则有助于创建清晰、易于理解和易于维护的 API。
第四章 资源规模和层级结构
本章涵盖:
- 什么是资源布局
- 资源关系的各种类型(引用、多对多等)
- 实体关系图是如何描述资源布局的
- 如何选择资源之间的正确关系
- 需要避免的资源布局反模式
正如我们在第1章中学到的,将我们的注意力从操作转向资源使我们能够通过利用简单的模式更轻松、更快速地熟悉API。例如,REST提供了一组标准动词,我们可以将其应用于许多资源,这意味着对于我们了解的每个资源,我们还可以掌握对该资源执行的五种不同操作(create、get、list、delete和update)。
尽管这很有价值,但这意味着我们需要更加慎重的定义API资源。选择正确的资源的关键部分是了解它们将来如何相互关联。在本章中,我们将探讨如何布局API中的各种资源、可用的选项以及选择正确的方式将资源彼此关联。此外,我们将讨论在考虑如何布局API中的资源时要避免的一些反模式(anti-patterns)(不应该做的事情)。让我们从具体了解资源布局的含义开始。
4.1 什么是资源布局
当我们谈论资源布局时(resource layout),通常指的是API中资源(或“事物”)的排列方式,定义这些资源的字段,以及这些资源如何通过这些字段相互关联。换句话说,资源布局是特定API设计的实体(资源)关系模型。例如,如果我们要构建一个聊天室的API,资源布局是指我们可能选择创建ChatRoom资源以及与ChatRoom有某种相关的User资源。我们感兴趣的是User和ChatRoom资源之间的关联方式。如果您曾经设计过具有各种表的关系数据库,这应该感觉很熟悉:您设计的数据库模式在本质上与API的表示方式非常相似。
虽然可能会说关系是唯一重要的事情,但实际上情况要复杂一些。虽然关系本身是对最终资源布局唯一有直接影响的因素,但还有许多其他因素间接影响布局。一个明显的例子是资源选择本身:如果我们选择不使用User资源,而是坚持使用按名称列出用户的简单列表(members: string[]),那么就没有其他资源可以布局,问题就被完全回避了。
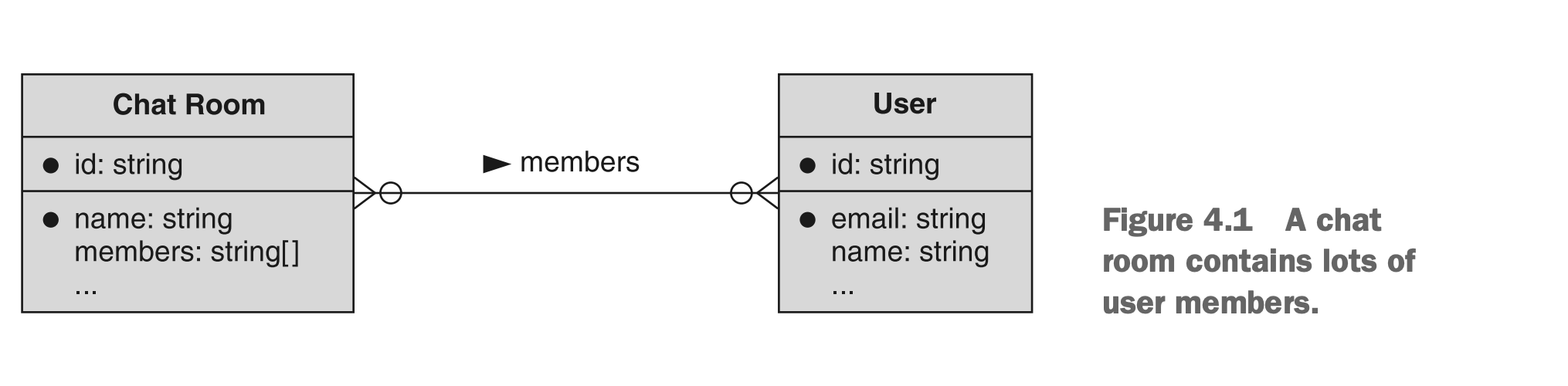
正如名称所示,API的资源布局在视觉上可能最容易理解,即将它看作由线连接在一起的方框。例如,图4.1显示了我们可能如何考虑聊天室示例,其中有许多用户和许多聊天室彼此相互连接。
图4.1 一个有很多成员的聊天室
如果我们正在构建一个在线购物API(例如,类似于亚马逊),我们可能会存储User资源以及他们的各种地址(用于运送在线购买的物品)和付款方式。此外,付款方式本身可能会引用付款方式的账单地址。这个布局如图4.2所示。
图4.2 用户,付款方式和地址之间有不同的对应关系
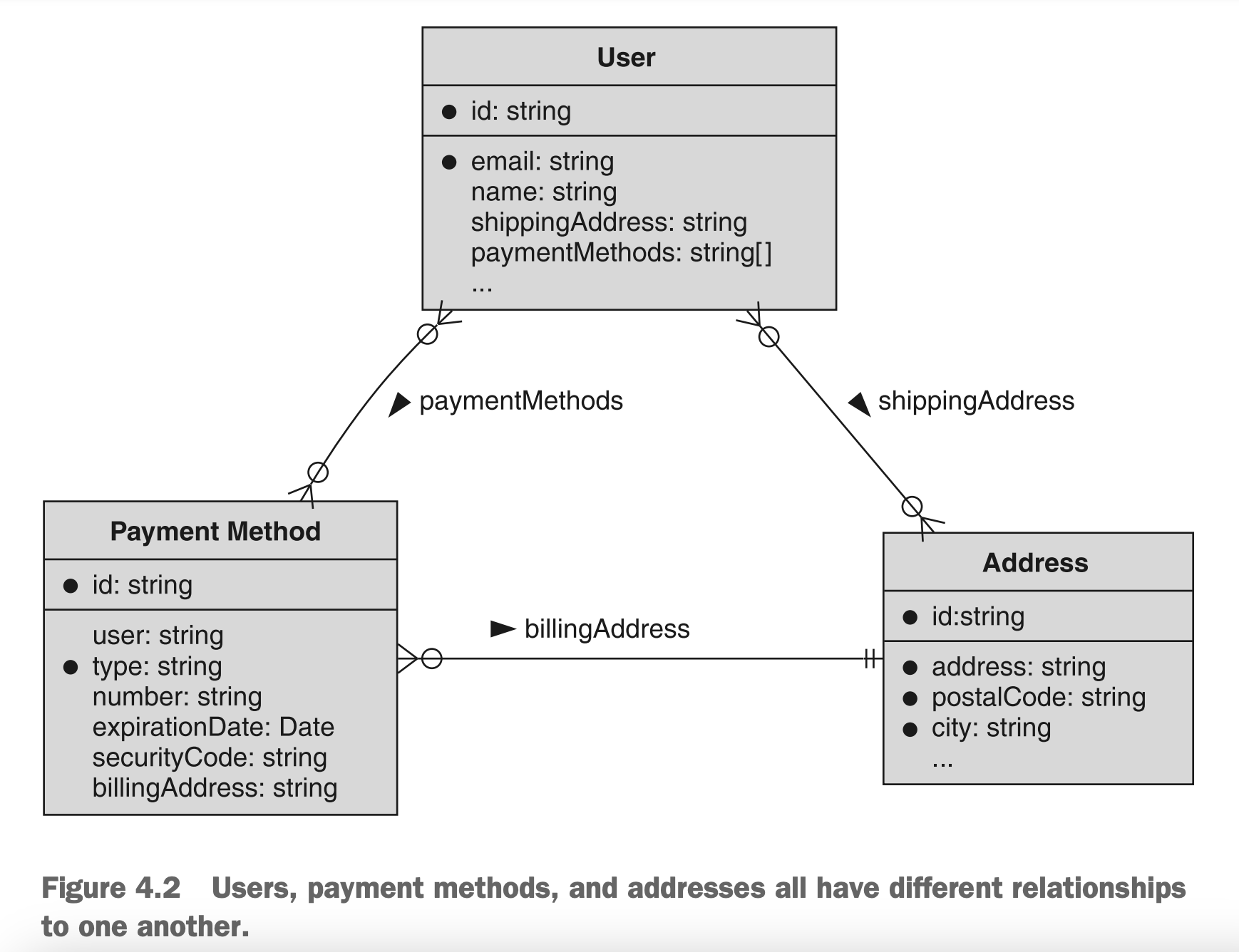
简而言之,要记住资源布局是一个广泛的概念,涵盖了所有我们为API定义的资源。最重要的是这些资源如何相互交互和关联。在下一节中,我们将简要介绍不同类型的关系以及每种类型可能提供的交互(和限制)。
4.1.1 资源关系的类型
在考虑资源布局时,我们必须考虑资源关系的多种方式。重要的是要注意,我们将讨论的所有关系都是双向的,这意味着即使关系看起来是单向的(例如,一条消息指向一个用户作为作者),反向关系仍然存在,即使它没有明确定义(例如,一个用户可以是多条不同消息的作者)。让我们直接开始看最常见的关系形式:引用。
引用关系
两个资源相互关联的最简单方式是通过简单的引用。这意味着一个资源引用或指向另一个资源。例如,在聊天室API中,我们可能有组成聊天室内容的Message资源。在这种情况下,每条消息显然会由单个用户撰写,并存储在消息的作者字段中。这将导致消息和用户之间存在简单的引用关系:消息有一个指向特定用户的作者字段,如图4.3所示。
图4.3 一个Message资源包含了对其作者(User资源)的引用
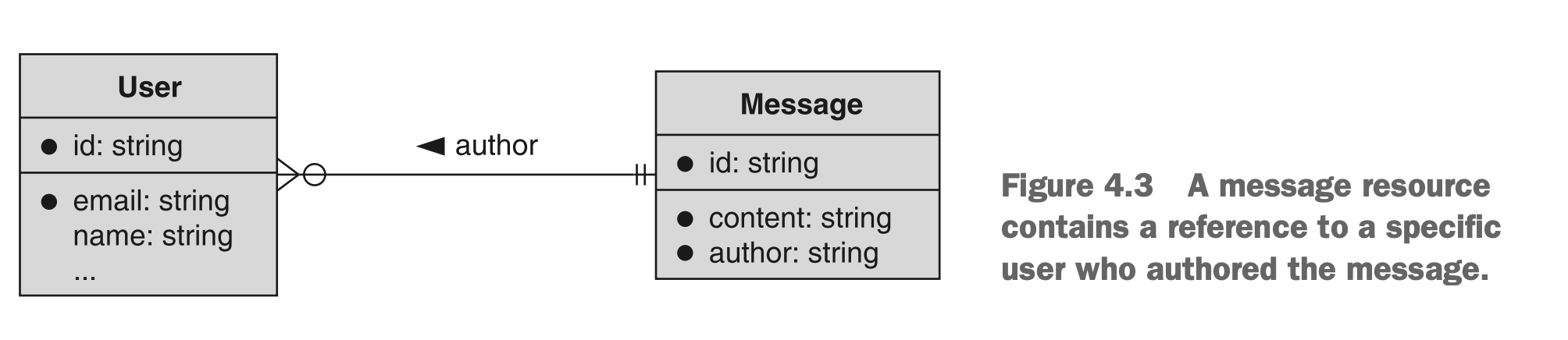
这种引用关系有时被称为外键(foreign key)关系,因为每个Message资源将指向一个确切的User资源作为作者。但正如前面提到的,一个User资源显然可以与许多不同的消息相关联。因此,这也可以被视为一对多关系,其中用户可能写多条消息,但每条消息始终有一个用户作为作者。
多对多关系
就像引用关系的一种更复杂的版本,一对多关系代表了每个资源指向另一个资源的多个实例的情况。例如,如果我们有一个用于组群对话的ChatRoom资源,这显然会包含许多个体用户作为成员。但是,每个用户也可以是多个不同聊天室的成员。在这种情况下,ChatRoom资源与用户之间存在一对多关系。ChatRoom指向很多User资源作为房间的成员,并且用户能够指向多个聊天室。
关于这种关系的工作原理的具体机制将在未来进行探讨(我们将在第三部分中看到这些),但这些多对多关系在API中非常常见,并且有几种不同的选项可以表示它们,每种选项都有其自己的优点和缺点。
自引用关系
在这一点上,我们可以讨论一种可能听起来奇怪但实际上只是引用的另一个特殊版本:自引用(self-reference)。顾名思义,在这种关系中,一个资源指向与其自身相同类型的另一个资源,因此"self"指的是类型而不是资源本身。实际上,这与普通的引用关系完全相同;但是,由于其典型的可视化表示(其中一个箭头指向资源本身),我们将其视为不同的类型,如图4.4所示。
图4.4 一个Employee资源指向其他Employee资源代表其经理和助理
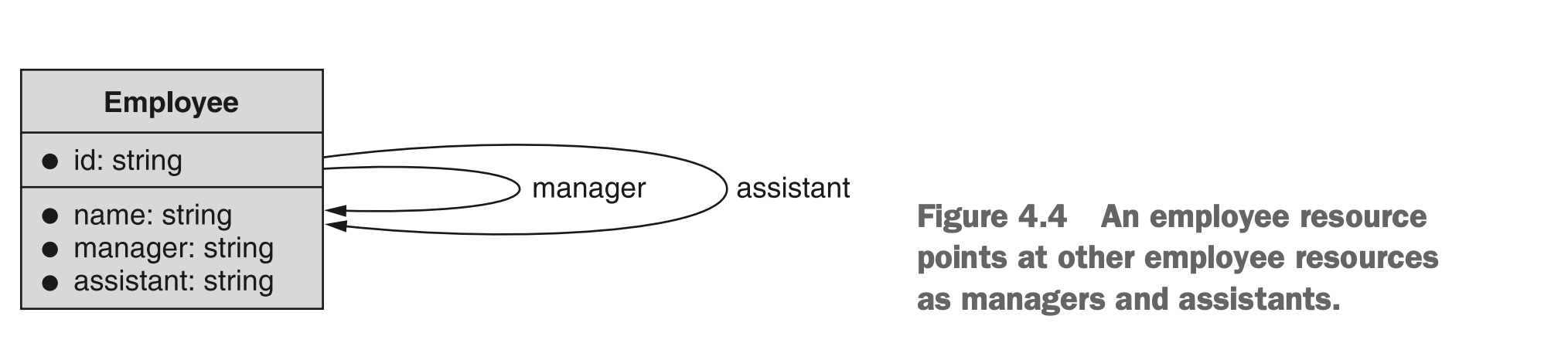
也许你会想知道为什么一个资源会指向与其自身相同类型的另一个资源。这是一个合理的问题,但实际上这种类型的关系出现的频率远远超出你的预期。自引用在层级结构中经常出现,在这种关系中,资源是树中的一个节点,或者在网络式API中,数据可以表示为有向图(例如社交网络)。
例如,想象一个用于存储公司目录的API。在这种情况下,员工相互指向以跟踪彼此的报告关系(例如,员工1向员工2报告)。该API还可能具有进一步的自引用,用于特殊关系(例如,员工1的助手是员工2)。在这些情况中,我们可以使用自引用来建模资源布局。
层级结构
最后,我们需要讨论一种非常特殊的关系,这是对标准引用关系的另一种理解:层级结构(hierarchies)。层级结构有点像一个资源指向另一个资源,但该指针通常指向上方,并且意味着不止一个资源指向另一个资源。与典型的引用关系不同,层级结构还倾向于反映资源之间的包含或所有权关系,可能最好使用计算机上的文件夹术语来解释。计算机上的文件夹(对于Linux用户来说是目录)包含许多文件,从这个意义上说,这些文件属于文件夹。文件夹还可以包含其他文件夹,有时会无限循环。
这可能看起来无害,但这种特殊的关系暗示了一些重要的属性和行为。例如,当你在计算机上删除一个文件夹时,通常所有包含在内的文件(和其他文件夹)也会被删除。或者,如果你被授予对特定文件夹的访问权限,这通常意味着对其中的文件(和其他文件夹)也有访问权限。这些相同的行为已经成为类似资源的预期行为。
在我们深入讨论之前,让我们看看层级结构是什么样子。实际上,在前几章中我们已经使用了层级结构的例子,因此我们不应该感到惊讶。例如,我们已经讨论过由许多消息资源组成的ChatRoom资源。在这种情况下,存在ChatRooms包含或拥有Messages的隐含层级关系,如图4.5所示。
图4.5 ChatRoom资源与Message资源的层级关系表明了一种从属关系
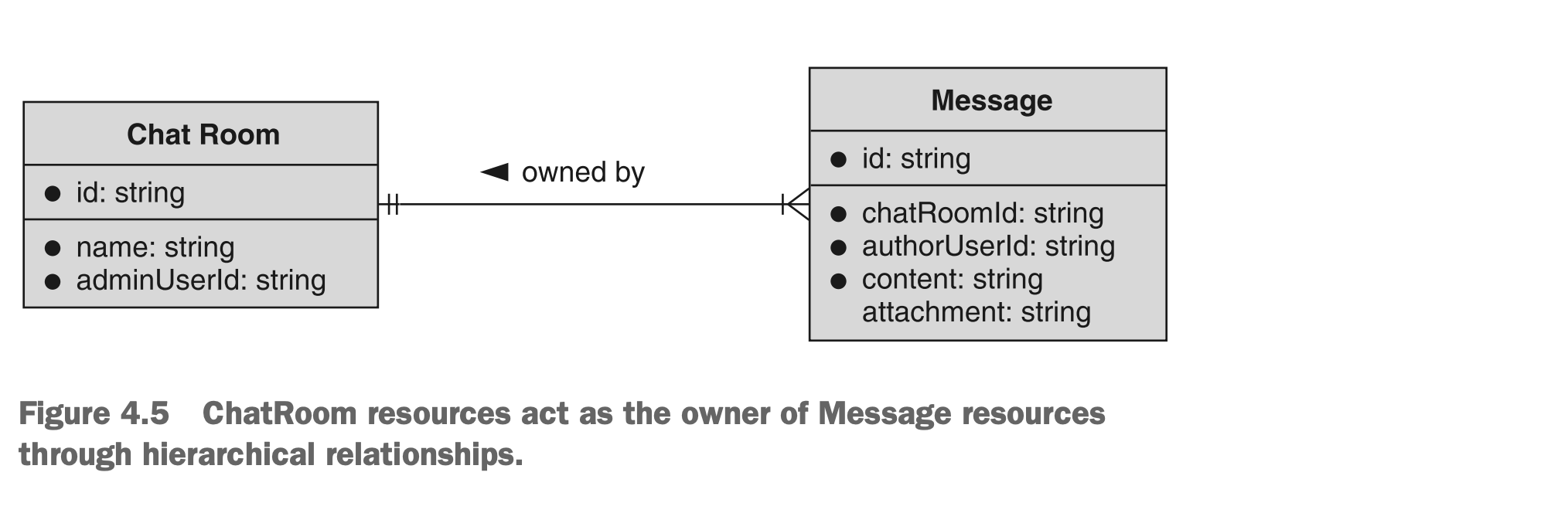
正如你可以想象到,这种结构通常暗示着有权限访问ChatRoom资源也将获得Message资源的访问权限。此外,通常假定删除ChatRoom资源会根据父子层级关系级联到Message资源。在某些情况下,这种级联效应是巨大的好处(例如,我们很高兴能够在计算机上删除整个文件夹,而不必首先删除里面的每个单独文件)。在其他情况下,级联行为可能会非常棘手(例如,我们可能认为我们正在授予对文件夹的访问权限,而实际上我们正在授予对该文件夹内所有文件的访问权限,包括子文件夹)。
总体而言,层级结构是复杂的,会引发许多棘手的问题。例如,资源可以更改父级吗?换句话说,我们可以将Message资源从一个ChatRoom资源移动到另一个ChatRoom资源吗?(通常,这是个坏主意)我们将在第4.2节中更深入地探讨层级结构及其缺点和优势。
4.1.2 实体关系图
在本章中,你可能已经看到了一些有趣的符号,它们出现在连接不同资源的线的末端。虽然我们没有时间深入研究UML(统一建模语言),但我们至少可以看一下其中一些箭头并解释它们的工作原理。
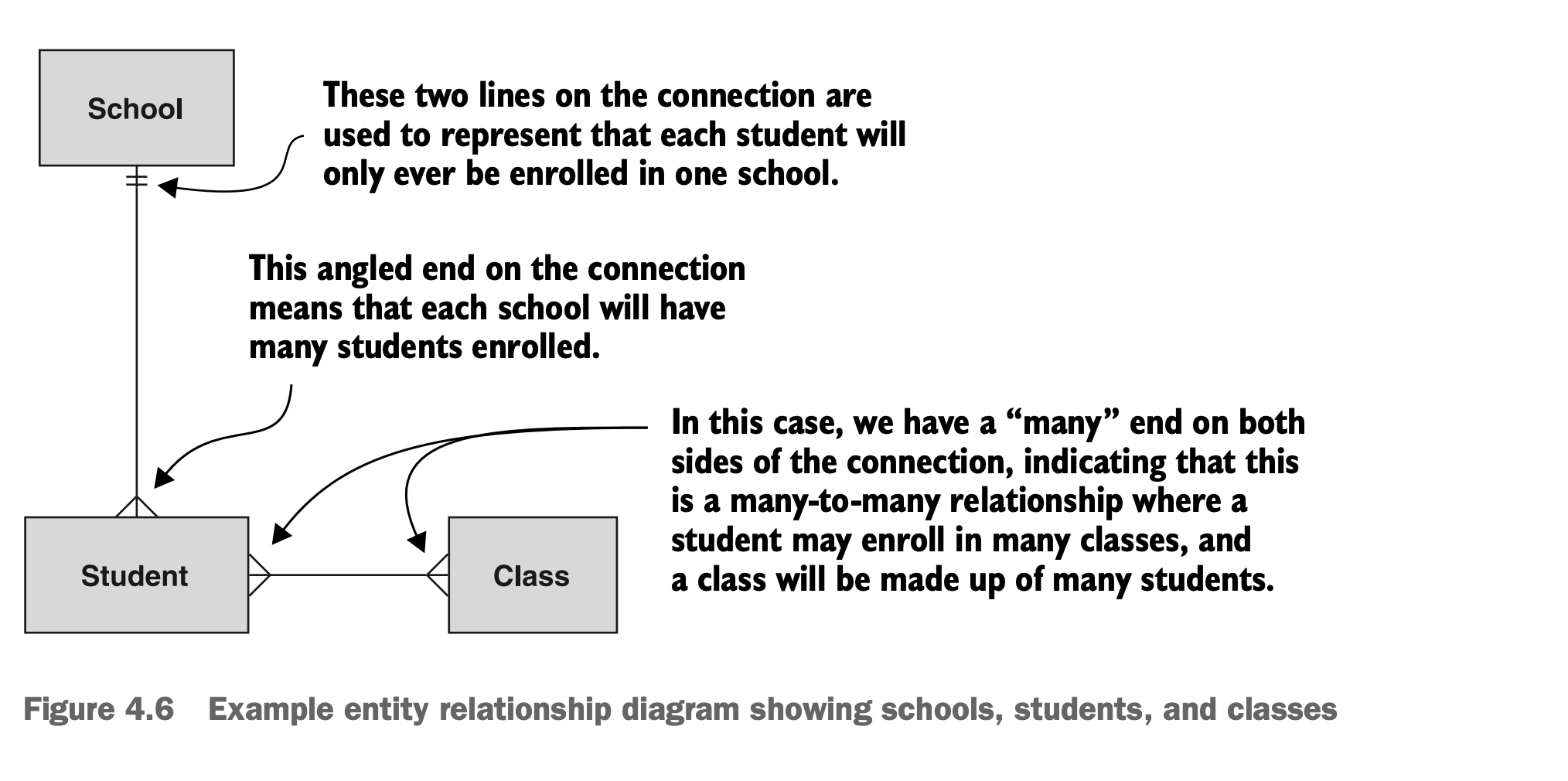
简而言之,相比于使用任意箭头从一个资源指向另一个资源,我们可以使箭头末端传达有关资源关系的重要信息。更具体地说,每个箭头末端可以告诉我们在另一端可能有多少资源。例如,图4.6显示学校有很多学生,但每个学生只上一所学校。此外,每个学生上很多课,每个班级包含很多学生。
图4.6 展示学校,学生和课程的实体关系图示例
虽然这两个符号显然是最常见的,但你可能偶尔会看到其他符号。这是为了涵盖资源数量为零的特殊情况(非必需资源)。例如,从技术上讲,一个班级可能由零个学生组成(反之亦然)。因此真实关系可能看起来更像图4.7。
图4.7 更新后的关系图表明一个学生可能不会参加任何课程,以及一门课程可能并没有学生选择

有时候理解这种类型的符号可能有点困难,因此澄清应该如何阅读每个连接器的方向可能有所帮助。阅读这些图表的最佳方法是从一个资源开始,沿着线走,然后查看线末端的连接器,最后到达另一个资源。重要的是要记住,您会跳过触及您起始资源的连接器符号。为了更清晰,图4.8显示了学校和学生资源之间的连接分成两个单独的图表,连接的方向写在线旁边。
图4.8 通过学校和学生资源说明如何阅读实体关系
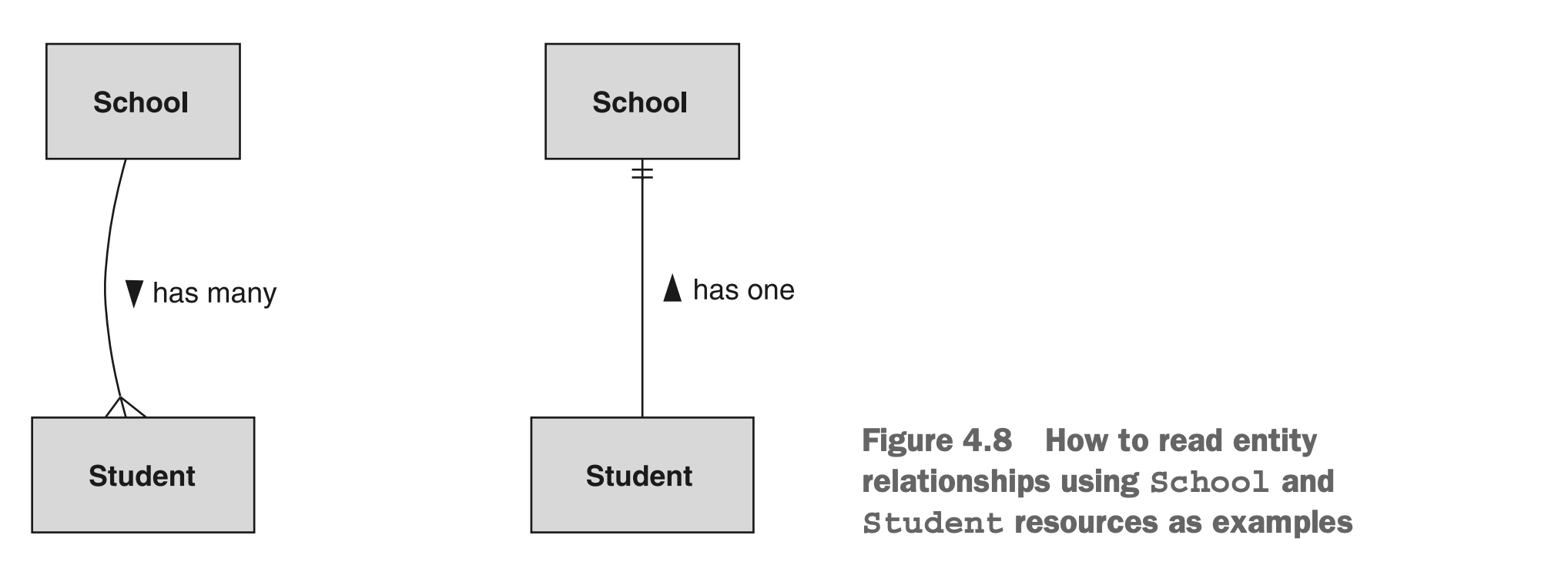
正如我们所看到的,一个学校有很多学生,而学生只有一个学校。为简单起见,我们将这两者合并到一个单独的图表和一条连接两者的线中,就像我们在之前的示例中看到的那样。
现在我们已经很好地掌握了如何阅读这些图表的方法,让我们开始更重要的工作,即通过选择资源之间的正确关系来建模我们的API。
4.2 选择正确的资源关系
正如我们在第4.1节中所学的,选择正确类型的资源关系通常取决于我们首先选择的资源,因此我们将在本节中将这两者联系在一起。让我们首先看一个重要的问题:我们是否需要资源关系?
4.2.1 你是否真的需要某种资源关系?
在构建API时,选择了对我们重要的事物或资源之后,下一步是决定这些资源之间的关系。通常人们会像规范化数据库模式一样连接所有可能需要连接的东西,以构建一个丰富的、互相关联的资源网络(通过各种指针和引用)。虽然这肯定会导致一个非常丰富和具有描述性的API,但随着API接收越来越多的流量并存储越来越多的数据,这也变得难以维持,并且可能出现严重的性能下降。
为了理解我们的意思,让我们想象一个简单的API,用户可以在其中关注彼此(例如,类似Instagram或Twitter的东西)。在这种情况下,User资源具有一个多对多的自引用,其中一个用户关注许多其他用户,每个用户可能有许多关注者,如图4.9所示。
图4.9 一个自引用的User资源,表示用户可以关注其他用户

这可能看起来是无害的,但当用户拥有数百万个关注者(并且用户关注数百万其他用户)时,情况可能变得相当混乱,因为这些类型的关系会导致对单一资源的更改影响数百万其他相关资源的情况。例如,如果某个著名人物删除其Instagram帐户,可能需要删除或更新数百万条记录(取决于底层数据库模式)。
这并不是说您应该以任何代价都要避免所有资源关系。相反,重要的是要在早期权衡任何给定关系的长期成本。换句话说,资源布局(和关系)并不总是没有成本的。就像在签署文件之前了解您的抵押贷款可能会具体花费多少钱一样重要,同样在设计过程中了解给定API设计的真实成本也很重要,而不是在设计的最后阶段了解。尽管在真正需要维护资源关系的场景中(例如前面的例子,存储关注者关系似乎非常重要)总会有办法缓解性能下降的问题,但谨慎定义API中的引用关系仍然是明智的。
换句话说,引用关系应该是有目的的,并且对于期望的行为而言是基本的。换句话说,这些关系永远不应该是偶然发生的、可选的,或者未来可能会需要的东西。相反,任何引用关系都应该是API实现其主要目标所必不可少的东西。
例如,像Twitter、Facebook和Instagram这样的服务是建立在用户相互关注的关系基础上的。用户之间的自引用关系对于这些服务的目标确实是至关重要的。毕竟,没有这种关系,Instagram将变成一个简单的照片存储应用程序。将其与直接消息服务进行比较:我们可以看到,尽管这种API在用户之间以聊天形式表现出某种关系,但它们对应用程序的重要性并不相同。例如,在聊天中涉及的两个用户之间建立关系很重要,但没有必要对所有潜在关系建立一个集合。
4.2.2 引用数据还是內联数据
假设某种资源关系对于您的API的行为和功能至关重要,那么我们就必须探讨并回答一些重要的问题。首先,我们需要探讨是否应该在API中内联数据(即在资源内存储副本)还是依赖引用(即仅保留对正式数据的指针)。让我们通过聊天室的案例展开说明。
假设每个聊天室必须有一个单一的管理员用户。我们有两个选择:我们可以通过引用字段(例如adminUserId)指向管理员用户,或者我们可以内联此用户的数据,并将其表示为ChatRoom资源的一部分。图4.10和4.11分别展示了两种情况。
图4.10 使用adminUserId指向管理员用户
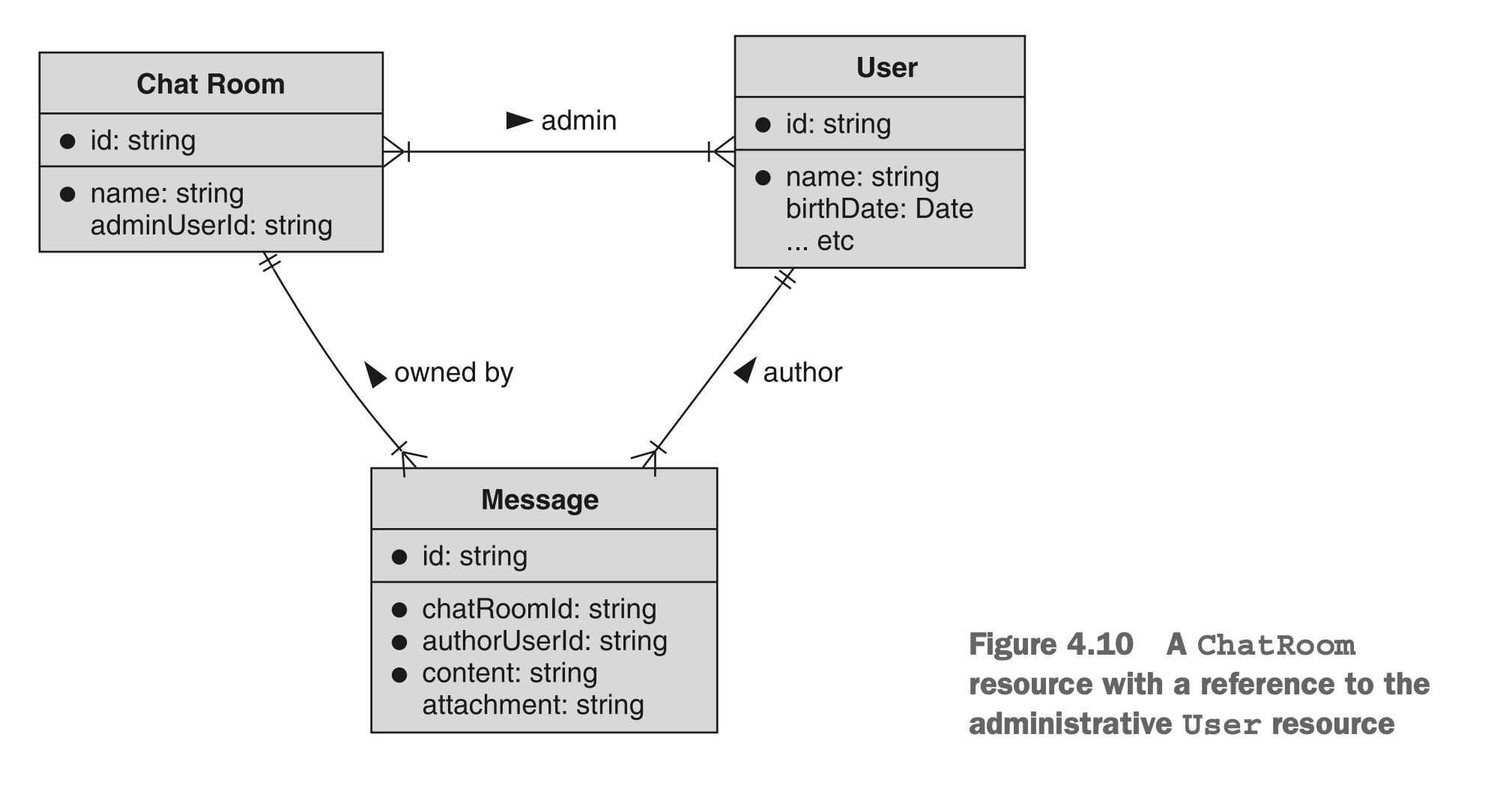
图4.11 将管理员用户数据內联至聊天室资源
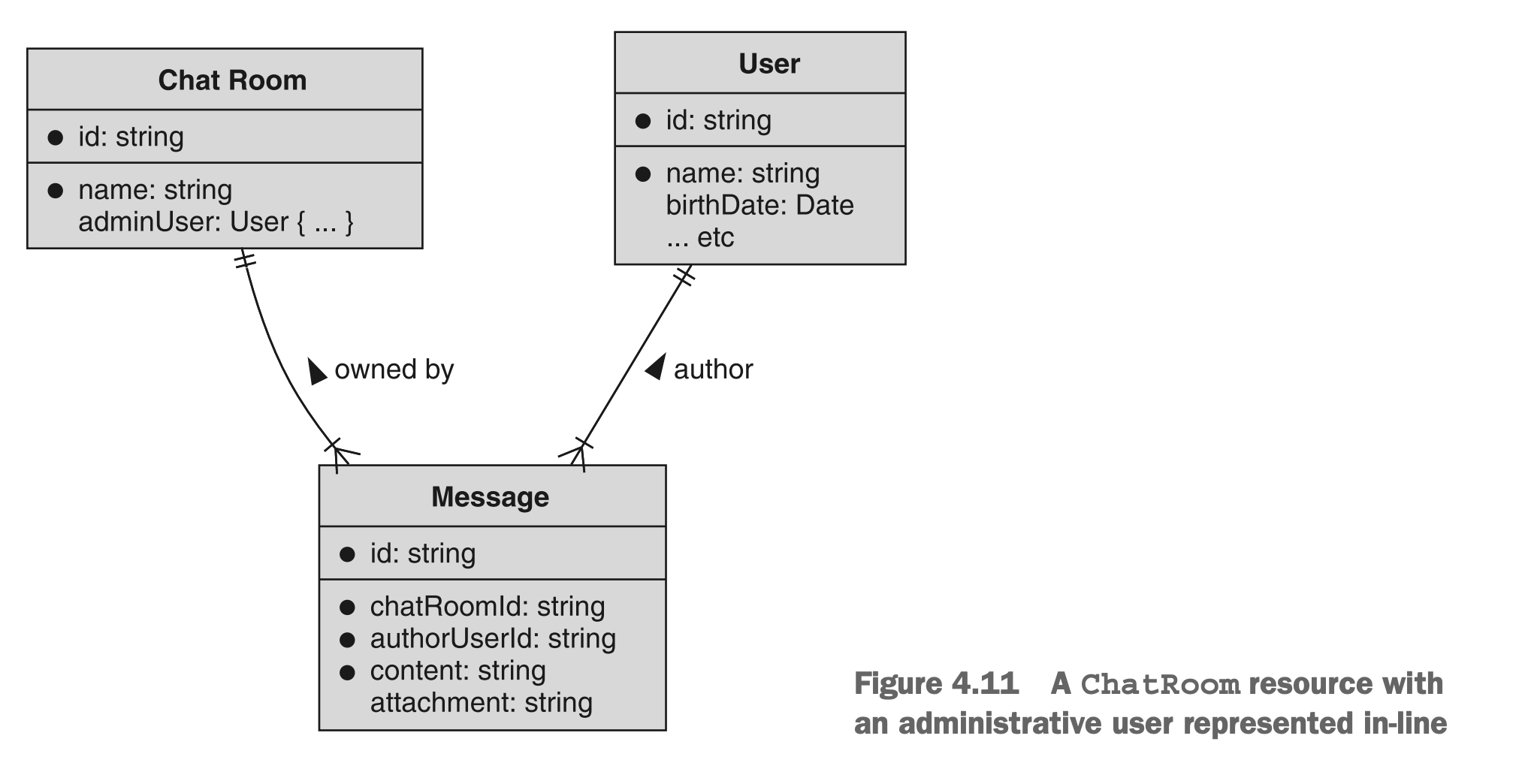
在第一个图表(图4.10)中,我们可以看到ChatRoom资源在指定管理员时指向User资源。另一方面,在第二个图表(图4.11)中,我们可以看到adminUser字段实际上包含有关管理员的信息。这引出了一个显而易见的问题:哪种方法更好?事实证明,答案取决于您提出的问题或执行的操作。
如果您想查看管理员的姓名,使用内联数据会更容易。为了了解原因,让我们看看在不同情况下为了获取这些信息我们需要做什么。
代码4.1 两种情况下获取管理员的方法
function getAdminUserNameInline(chatRoomId: string): string {
let chatRoomInline = GetChatRoomInline(chatRoomId);
return chatRoomInline.adminUser.name;
}
function getAdminUserNameReference(chatRoomId: string): string {
let chatRoomRef = GetChatRoomReference(chatRoomId);
// 对于引用的情况,如果我们想要获取有关管理员的更多信息,我们需要进行第二次查找。
let adminUser = GetAdminUser(chatRoomRef.adminUserId);
return adminUser.name;
}
这两个函数中最明显的区别是需要网络响应的实际API调用数量。在第一种情况中,数据以内联方式返回,我们只需要一个API调用即可检索所有相关信息。而在第二种情况中,我们首先必须检索ChatRoom资源,然后才知道我们感兴趣的用户是谁。之后,我们必须检索User资源以获取姓名。
这是否意味着最好总是将数据内联?并非完全如此。这是一个例子,我们需要两倍的API调用次数才能获取我们感兴趣的信息。但如果我们并不经常关心那些信息呢?如果是这样,那么每当有人请求ChatRoom资源时,我们都会发送大量字节,而大部分字节却被无视了。换句话说,每当有人请求ChatRoom资源时,我们还要告诉他们该房间管理员的User资源的所有信息。
这可能看起来并不是什么大问题,但如果每个用户也将他们所有的朋友(其他User资源)以内联方式存储呢?在这种情况下,将聊天室的管理员与之一起返回实际上可能导致大量额外的数据。此外,当生成所有这些额外的内联数据时,通常需要额外的计算工作(通常来自底层需要连接数据的数据库查询),而这种数据可能以不可预测的方式迅速增长。那么我们该怎么办呢?
不幸的是,这将取决于您的API正在做什么,因此这是一个判断性决策(主观决策)。一个很好的经验法则是优化常见情况,而不影响高级情况的可行性。这意味着我们需要考虑相关资源是什么,它现在有多大,以及它可能会变得多大,并决定在响应中包含管理员信息有多重要。在这种情况下,典型用户可能并不经常查找他们聊天室的管理员是谁,而是更专注于向朋友发送消息。因此,内联这些数据可能并不是非常重要。另一方面,User资源可能非常小,因此如果API经常使用这些数据,内联这些数据可能并不是一个很大的问题。
话虽如此,我们还没有涉及到另一种重要的关系类型:层级结构。让我们看看应该何时选择层级结构关系。
4.2.3 层级结构
正如我们之前所了解的,层级关系是一种非常特殊的引用关系,是父资源与子资源之间的关系,而不是两个一般相关的资源。这种关系的最大区别在于操作的级联效应以及从父级到子级的行为和属性的继承。例如,通常删除父资源会意味着删除子资源。同样,对父资源的访问(或无访问权限)通常意味着对子资源的相同级别的访问。这种关系的独特而潜在有价值的特性意味着它具有很大的潜力,无论是积极的还是消极的。
我们如何决定何时将资源安排在层级关系而不是简单关系中呢?假设我们已经决定对某种特定关系的模拟是构建某个API的基础(参见第4.2.1节),我们实际上可以依赖模拟的行为作为一种关系是否合适的重要指标。
例如,当我们删除一个聊天室时,我们几乎肯定也希望删除属于该聊天室的Message资源。此外,如果有人被授予访问ChatRoom资源的权限,如果他们没有权限查看与该聊天室相关联的Message资源,那么这似乎并不合理。这两个指标意味着我们几乎肯定要将这种关系建模为一个适当的层级结构。
同样,还有一些迹象表明你也不应该使用层级关系。由于子资源只能有一个父资源,那么显然已经有一个父资源的资源不能再有另一个父资源。换句话说,如果您考虑的是一对多的关系,那么层级结构肯定不是一个好的选择。例如,Message资源应该始终属于一个单一的聊天室。如果我们想将单个Message资源与许多ChatRoom资源相关联,那么层级结构可能不是正确的模型。
这并不是说资源只能指向一个资源。毕竟,大多数资源都将是另一个资源的子资源,仍然可能被其他资源引用。例如,想象一下ChatRoom资源属于公司(这个示例的新资源类型)。公司可能有保留策略(由RetentionPolicy资源表示),指定消息在被删除之前要存留多长时间。这些保留策略将是单个公司的子资源,但可能被该公司中的任何ChatRoom资源引用。如果这让您感到困惑,请查看图4.12中的资源布局图。
图4.12 将公司范围的保留策略应用于聊天室的资源布局图
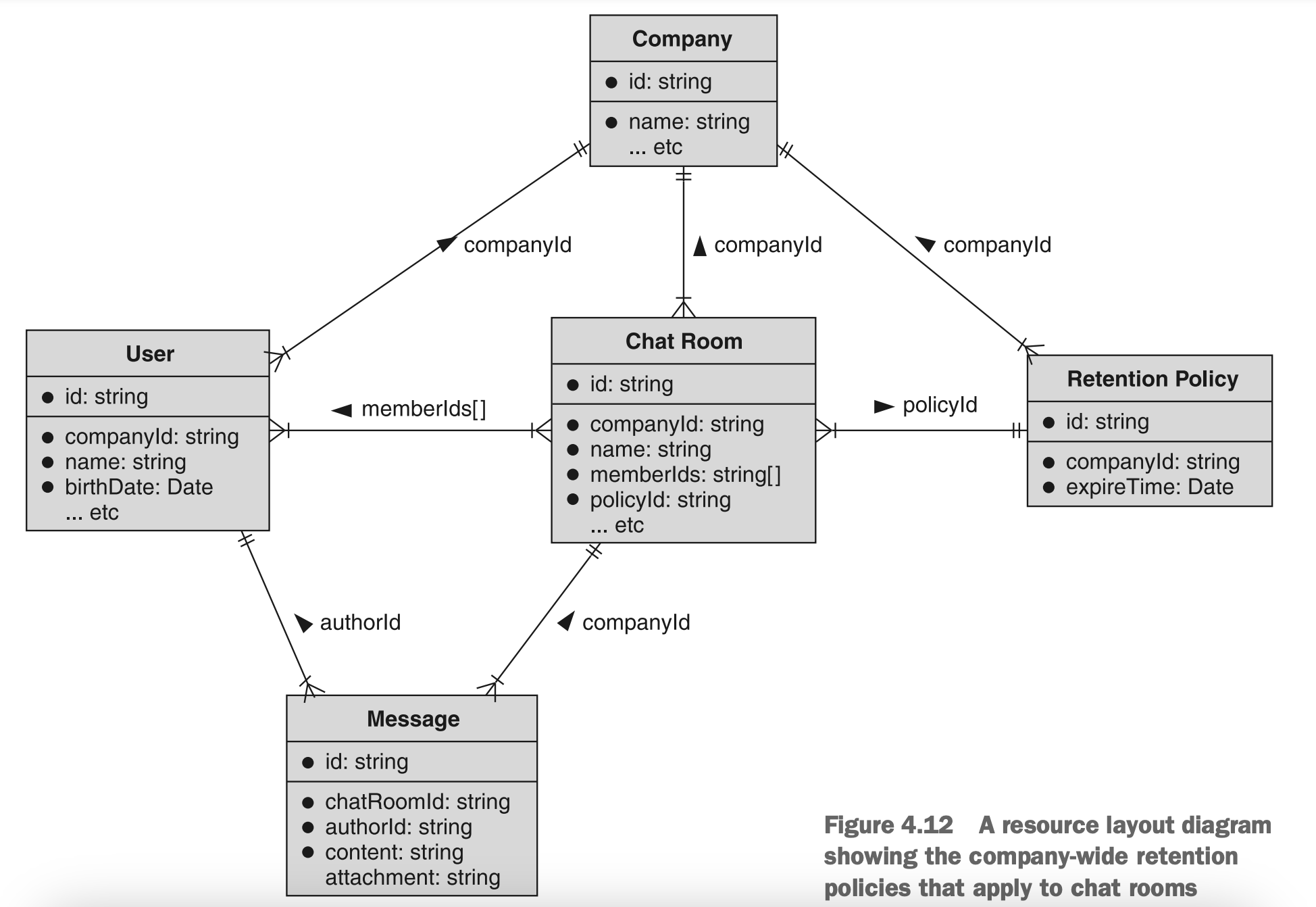
正如您在这里所看到的,User、ChatRoom和RetentionPolicy资源都是Company资源的子资源。同样,Message资源是ChatRoom资源的子资源。但是RetentionPolicy是可重用的,并且可以应用于许多不同的聊天室。
希望在这一点上,您已经对何时依赖引用与层级结构(以及何时内联信息而不是使用引用)有了一个很好的了解。但在探讨这些主题之后,我们在设计API时往往会陷入一些条件反射的反应。让我们花一点时间看看一些资源布局的反模式以及如何避免它们。
4.3 反模式
与大多数主题一样,API设计存在通用的笼统套路,可以在所有情况下轻松套用,但这些行为往往会使我们误入歧途。毕竟,盲目套用比深入思考API设计并决定如何最好地安排资源以及它们之间的关系要容易得多。
4.3.1 万物皆资源
很多人有时会忍不住给最微小的概念创建资源。通常,这种做法的出现是因为人们认为任何数据类型都必须对应一个适当的资源。例如,想象我们有一个API,可以在图像上存储注释。对于每个注释,我们可能希望存储注释区域(可能以某种边界框住特定面积)以及构成实际注释内容的注释条目列表。
在这一点上,我们有四个独立的概念要考虑:图像、注释、边界框和条目。问题是,其中哪些应该是资源,哪些应该仅仅作为数据类型?一个条件反射的反应是使一切都成为资源,不管是什么。这可能最终看起来像图4.13中所示的资源布局图。
图4.13 将所有概念都作为资源进行布局的示例
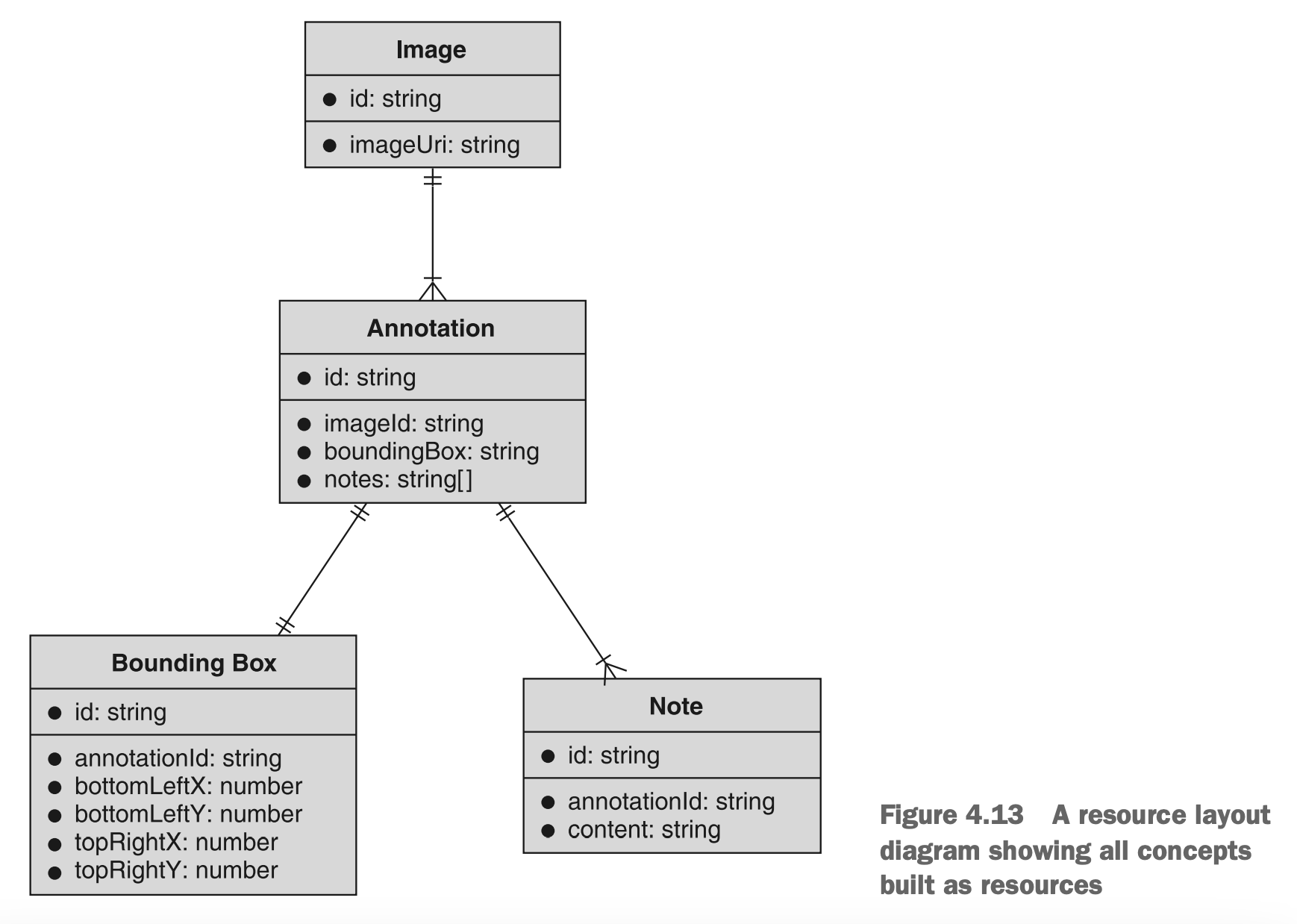
现在我们有四个完整的资源,它们具有完整的资源生命周期。换句话说,我们需要为这些资源中的每一个实现五种不同的方法,总共有20个不同的API调用。这带来了一个问题:这是正确的选择吗?毕竟,我们真的需要为每个边界框提供独立的标识符吗?我们真的需要为每个条目创建单独的资源吗?
如果我们更深入地思考这个布局,我们可能会发现两个重要的问题。首先,BoundingBox资源与注释是一对一的关系,因此将其放入单独的资源中几乎没有价值。其次,注释资源的条目列表不太可能变得非常大,因此通过将其表示为资源,我们并没有获得太多的好处。如果我们将这一点考虑在内,我们就会得到一个更简单的资源布局。这意味着我们实际上只需要考虑两个资源(而不是四个),这对于理解和构建API都更容易。图4.14和代码4.2显示了资源布局图的简化版本。
图4.14 将资源简化为2个后的布局示例
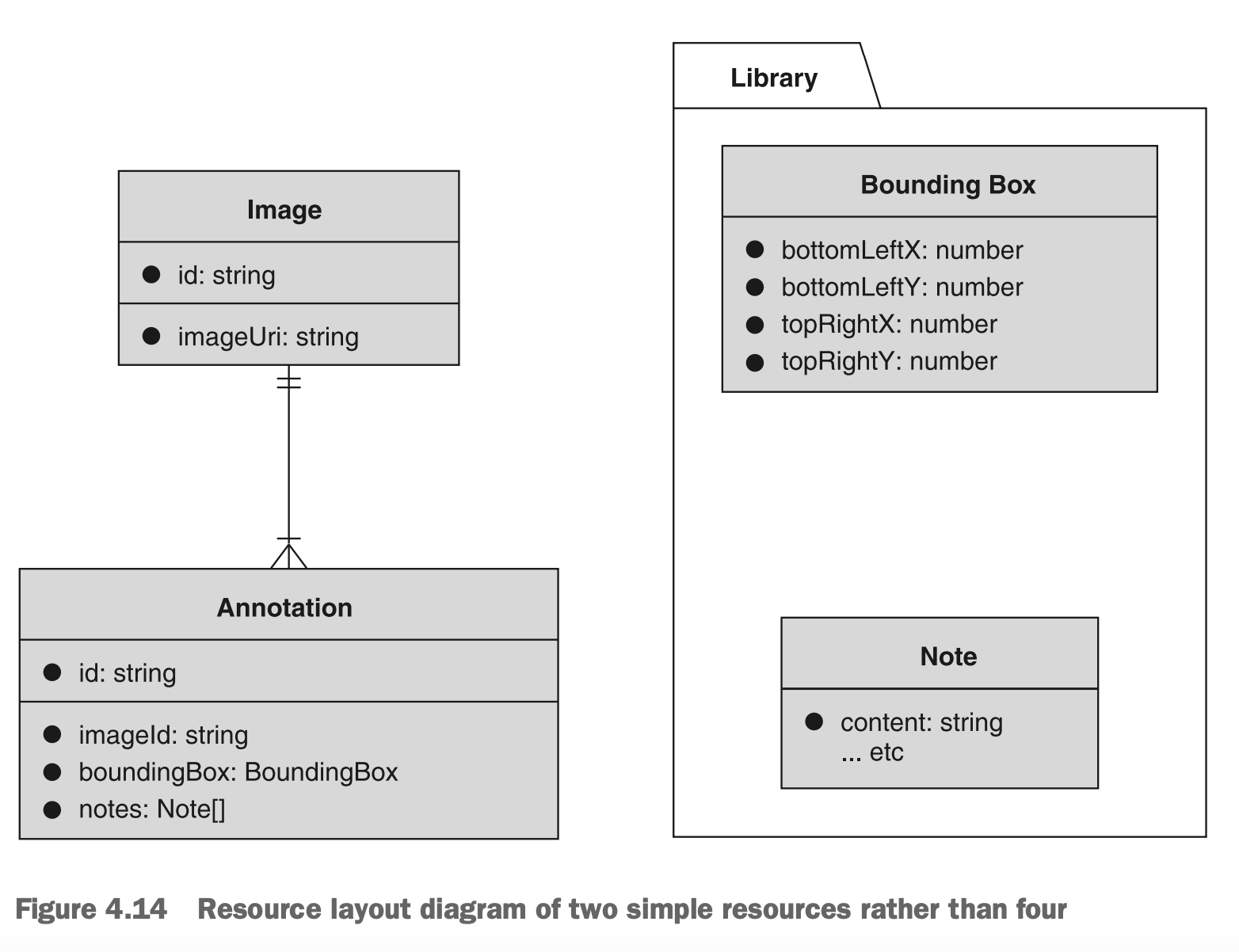
代码4.2 通过內联数据简化后的接口表示
// 前两个为实际定义的资源,注意id字段
interface Image {
id: string;
}
interface Annotation {
id: string;
boundingBox: BoundingBox;
notes: Note[];
}
// 后三个不是资源,他们只是数据类型
interface BoundingBox {
bottomLeftPoint: Point;
topRightPoint: Point;
}
interface Point {
x: number;
y: number;
}
interface Note {
content: string;
createTime: Date;
}
一个好的经验法则是避免两个问题。首先,如果出了与之关联的资源外,您无需与某个资源独立交互,那么它可能仅作为数据类型就可以。在此示例中,不太可能有人需要在图像之外操纵边界框,这意味着这可能边界框很适合作为数据类型。其次,如果您想要与某个事物独立交互(在这种情况下,您可能希望删除单个注释条目或单独创建新条目),如果它可以内联(请参阅第 4.2.2 节),那么这可能是一个不错的选择。在这种情况下,条目资源足够小,并且预计不会在每个注释中增长为一个大集合,这意味着将它们内联而不是表示为独立资源可能是安全的。
4.3.2 深层结构
下一个要避免的常见反模式与层级结构有关。层级关系通常看起来非常强大和有用,我们会尽量在所有可能的地方使用它们。然而,过于深的层级结构可能会对所有相关人员造成困惑,并且难以管理。
例如,让我们想象一下,我们正在构建一个用于管理大学课程目录的系统。我们需要跟踪不同的大学,课程所属的学院或项目(例如,护理学院或工程学院),可用的课程,提供课程的学期,以及各种课程文件(例如,教学大纲)。追踪所有这些信息的一种方法是将所有内容放在单一的层级结构中,如图4.15所示。
图4.15 关于课程目录的深层结构
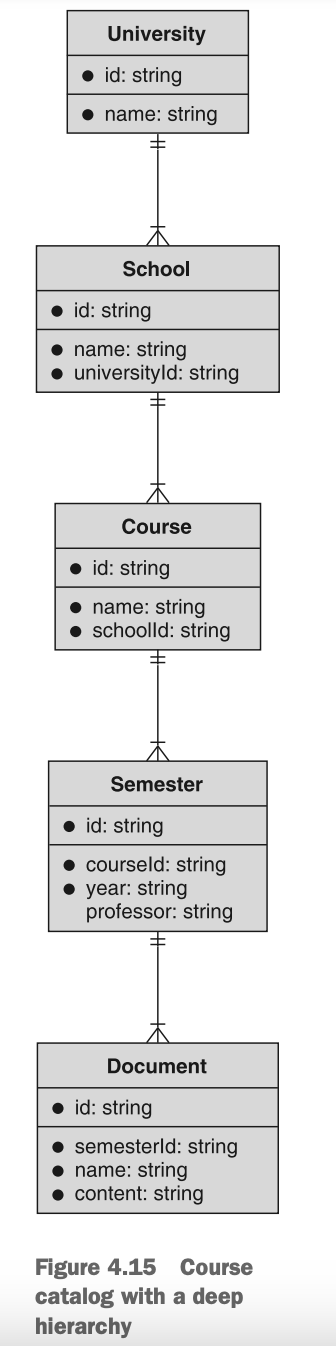
尽管从技术上讲,这样做是完全可行的,但理解和记住所有不同的父级实在是相当困难。这还意味着我们现在需要知道相当多的信息才能找到一个单一的文档(有关此主题的更多讨论,请参见第6.3.6节),这可能很难存储和回忆。但这里更大的问题是,在这里使用层级结构实际上并不是完成工作所必需的。换句话说,我们可能可以在没有这么多层级结构的情况下创建同样出色的API。
如果我们决定关键部分是大学、课程和文档呢?在这个世界中,学院成为课程的一个字段,学期也是如此。我们可以通过反问学院和学期层级结构是否真的那么关键来发现这一点。
例如,我们计划使用层级结构行为来做什么?我们计划经常删除学院吗?(可能不会。)学期呢?(同样,可能不会。)最有可能的情况是我们希望看到被列出的给定课程的所有学期。但我们可以通过基于课程标识进行过滤来实现这一点,同样,通过给定学院ID列出课程也是如此。
请记住,这并不是说我们应该完全摆脱这些资源。就学期来说,我们不太可能需要一个可用学期的列表以进行查询,但学院可能是值得保留的内容。建议的变更是改变学院和课程之间的关系,从层级结构关系变为引用关系。这种新的(更浅的)层级结构显示在图4.16中。
图4.16 关于课程目录的更浅的层级结构
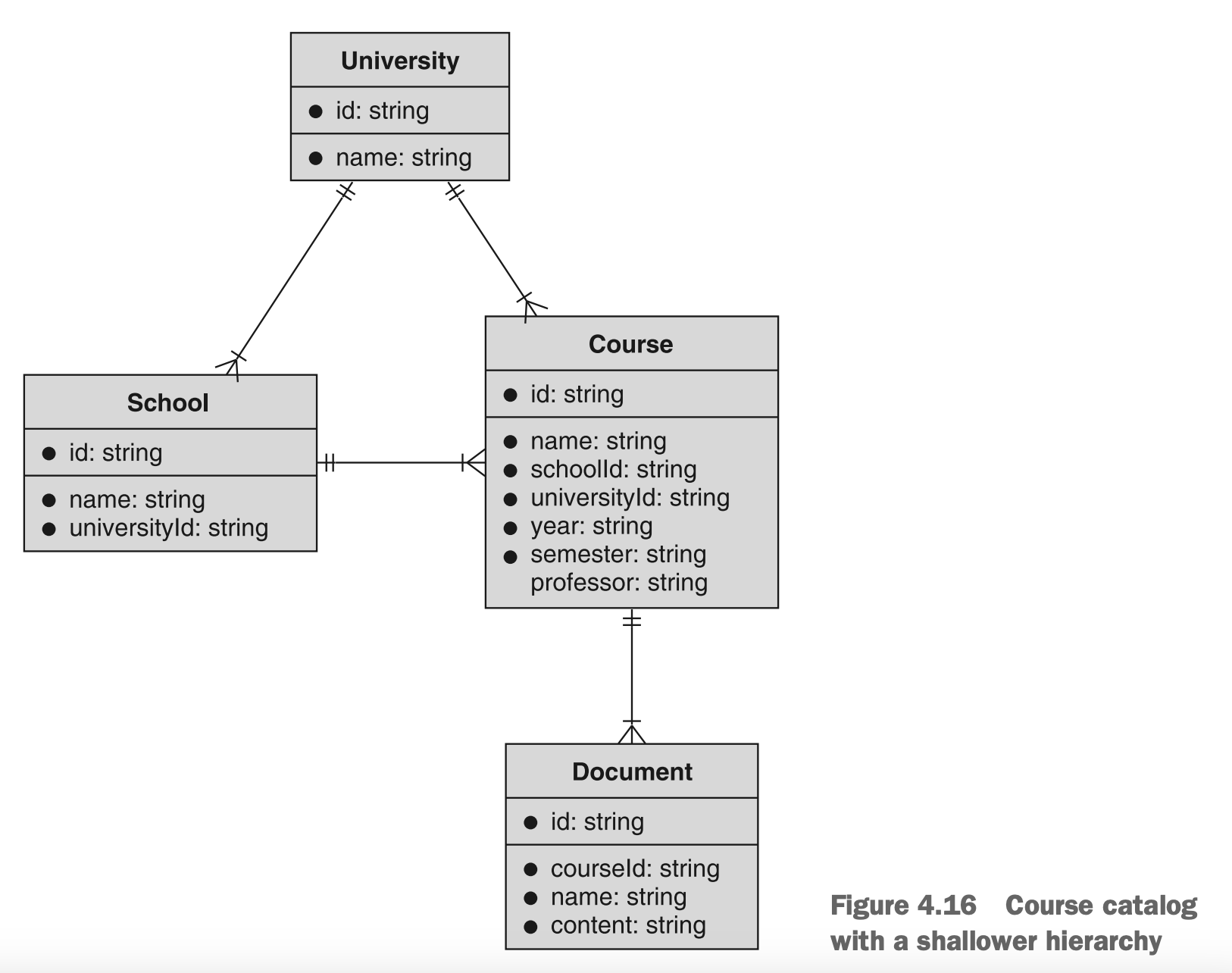
通过以这种方式(即更浅的方式)安排我们的资源,我们仍然可以执行一些操作,比如授予对给定课程实例的所有文档的访问权限,或者列出给定学期的所有课程,但我们已经将层级结构减少并给到真正受益的部分。
4.3.3 內联一切
随着非关系型数据库的出现,尤其是大规模的键值存储系统,人们往往倾向于去范式化(或内联)所有数据,包括过去会被整齐地组织到单独的表中并通过精巧的SQL查询进行连接的数据。尽管有时将信息折叠到单一资源中而不是使每个信息都成为单独的资源是有意义的(正如我们在第4.3.2节中学到的),但将太多信息折叠到单一资源中可能会像将每个信息分开成单独的资源一样有害。
这其中一个主要原因与数据完整性有关,这也是非关系型数据库中去范式化模式常见的问题。例如,假设我们正在构建一个图书馆API,用于存储不同作者编写的书籍。我们可以选择有两个资源,Book和Author,其中Book资源指向Author资源,如图4.17所示。如果我们选择内联这些信息,我们可能会直接在Book资源上存储作者的姓名(和其他信息),如图4.18所示。
图4.17 书籍和作者分别作为资源
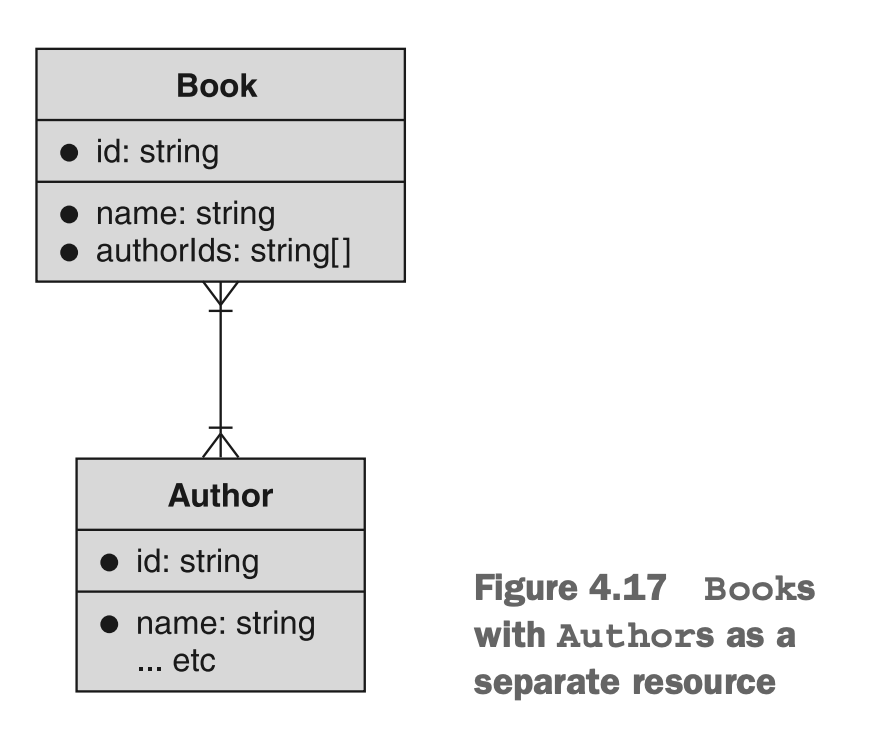
图4.18 将作者內联到书籍资源中
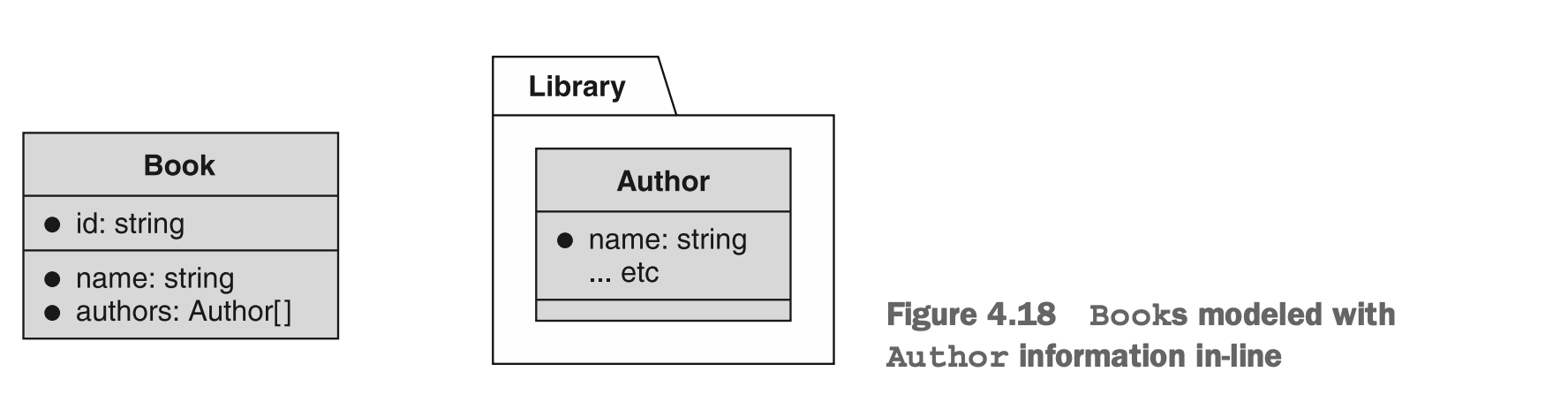
正如我们之前学到的(参见第4.2.2节),像这样内联数据确实很有价值,但它也可能导致一些真实的问题。例如,当您更新书中的一位作者的姓名时,它是否会更新他们所写的所有书籍中的姓名?对于这个问题的答案可能会取决于您的实现,但我们必须提出这个问题就意味着这可能会引起混淆。换句话说,当我们内联数据时,这些数据仍然会在其他资源之间共享(例如,编写了多本书的作者),我们就打开了一个可怕的潘多拉魔盒,我们必须决定API的用户应该如何更新那些共享的数据(例如,作者的姓名)。虽然有很好的方法来解决这些问题,但这实际上不是我们应该首先担心的问题。
4.4 练习
- 想象一下,您正在构建一个书签API,其中包含特定在线URL的书签,并可以将这些书签放入不同的文件夹中。您是将其建模为两个单独的资源(Bookmark和Folder),还是一个单一的资源(例如Entity),并通过内联的类型字段指明其是作为文件夹还是书签?
- 想出一个例子并绘制一个实体关系图,涉及到一个多对多关系、一个一对多关系、一个一对一关系以及一个可选的一对多关系。确保使用正确的符号来表示连接器。
本章总结
- 资源布局指的是API中资源之间的排列和关系。
- 要抵制连接API中的每个资源的冲动,只有在它们对API提供重要功能时才存储资源关系。
- 有时为一个概念存储一个单独的资源是有意义的。而其他时候,最好将数据内联并将概念保留为数据类型。这个决定取决于您是否需要以原子方式(atomically)与该概念进行交互。
- 避免过于深层次的层级关系,因为它们可能难以理解和管理。
第五章 数据类型和默认值
本章涵盖:
- 我们对数据类型的理解
- 空值与不设置任何值之间的区别
- 对各种基本数据类型和集合数据类型的探讨
- 如何处理各种数据类型的序列化
在设计任何API时,我们总是要考虑接受、理解和可能存储的数据类型。有时这听起来可能相当简单:一个名为“name”的字段可能只是一串字符。然而,在这个问题中隐藏着复杂的世界。例如,字符串应该如何表示为字节(事实上有很多选项)?如果在API调用中省略了名称会发生什么?这是否与提供一个空的名称有所不同(例如,{ "name": "" })?在本章中,我们将探讨在设计或使用API时几乎肯定会遇到的各种数据类型,以及如何最好地理解它们的基础数据表示方式,以及如何以明智且直观的方式处理各种类型的默认值。
5.1 数据类型介绍
数据类型是几乎每种编程语言中的重要方面,它告诉程序如何处理一块数据以及它应该如何与语言或类型本身提供的各种运算符进行交互。即使在具有动态类型的语言中(其中单个变量可以充当许多不同的数据类型,而不仅仅是限制为一个类型),在单个时间点的类型信息仍然非常重要,它指导编程语言应该如何处理变量。
然而,在设计API时,我们必须摆脱仅考虑单一编程语言的思维模式,因为我们API的主要目标之一是让使用任何编程语言的人与服务进行交互。我们通常通过依赖某种序列化协议来实现这一点,该协议将我们选择的编程语言中的数据的结构化表示转换为一种与语言无关的序列化字节表示,然后将其发送到请求它的客户端。在另一端,客户端反序列化这些字节并将它们转换回内存表示,以便他们可以用他们使用的语言进行交互(这可能与我们使用的语言相同,也可能不同)。请参见图5.1了解此过程。
图5.1 数据从API服务端转移至客户端
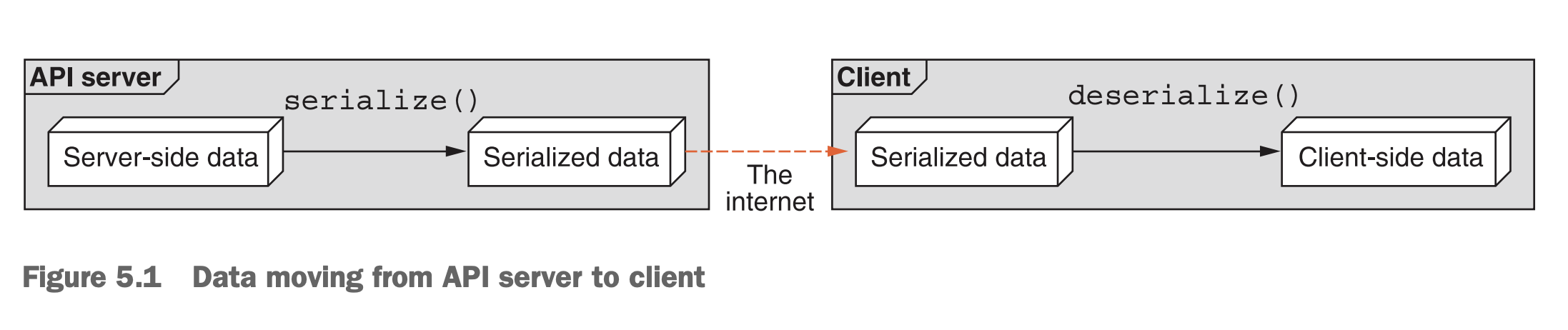
虽然这个序列化过程提供了巨大的好处(基本上允许API被任何编程语言使用),但它并非没有缺点。最大的缺点之一是由于每种语言的行为略有不同,因此在翻译过程中会有一些信息丢失。换句话说,由于不同编程语言的功能差异,所有序列化协议在某种程度上都会有“损失”。
这将我们带回到数据类型的重要性以及如何在API中使用它们。简而言之,仅依赖于我们选择的编程语言提供的数据类型是不够的,尤其是当考虑到使用Web API的人时。相反,我们必须考虑我们选择的序列化格式(最常见的是JSON)提供的数据类型,以及在它不能满足我们需求的情况下如何扩展该格式。这意味着我们需要决定要发送到客户端和从客户端接收的数据类型,并确保对它们进行足够详细的文档化,以便客户端永远不会对它们的行为感到惊讶。
这并不是说Web API必须像关系数据库系统那样具有严格的模式;毕竟,现代开发工具中最强大的功能之一就是动态无模式结构和数据存储提供的灵活性。然而,重要的是要考虑我们正在交互的数据类型,并在必要时用额外的注释来澄清。没有这些有关数据的额外上下文,我们可能会陷入猜测客户端实际意图的困境。例如,对于数字值,a + b可能会以一种方式工作(例如,2 + 4可能会得到6),但对于文本值,它可能会完全不同(例如,“2” + “4”可能会得到“24”)。如果没有这种类型上下文,当客户端使用+运算符时,我们将被迫猜测它的意图:是加法还是连接?而且如果一个值是数字而另一个值是字符串呢?这可能导致更多的猜测。那么,如果一个值完全被省略呢?
5.1.1 省略 vs NULL
令人惊讶的是,最令人困惑的一个方面是数据缺失而不是存在的情况。首先,在许多序列化格式中,存在一个null值,它是一个表示非值的标志(例如,字符串可以是值,也可以是文字null)。那么,例如,API在尝试添加null和2时应该如何行为?任何使用支持此类null值的序列化格式的API都需要决定如何最好地处理其API的此类输入。它应该假装null在数学上等同于0吗?试图添加null和"value"呢?在这种情况下,null是否应该被解释为空字符串("")并尝试连接它呢?
更糟糕的是,动态数据结构(例如JSON对象)有一个新问题:如果值根本不存在怎么办?换句话说,与显式设置为null的值相比,如果存储该值的键完全缺失了呢?这是否被视为与明确的null值相同?为了了解这意味着什么,想象一下你有一个期望包含名称和颜色的Fruit资源,两者都是字符串数据类型。考虑以下示例JSON对象以及API可能为资源的颜色值辨别出的值:
fruit1 = { name: "Apple", color: "red" };
fruit2 = { name: "Apple", color: "" };
fruit3 = { name: "Apple", color: null };
fruit4 = { name: "Apple" };
如您所见,第一个颜色值是明显的(fruit1.color == "red")。然而,对于其他情况应该怎么办呢?空颜色("")是否与显式null颜色相同(fruit2.color是否与fruit3.color有所不同)?那么缺少颜色值的水果呢?fruit3.color是否与fruit4.color有所不同?这些可能只是JSON的缺陷,然而,它们确实存在于许多其他序列化格式中(例如,Google的Protocol Buffers [https://opensource.google/projects/protobuf] 在这个领域有一些令人困惑的行为),它们提供了每个API都必须解决的场景,否则可能会对使用API的人产生极大的不一致和混乱。换句话说,您不能简单地假设序列化库会做正确的事情,因为几乎可以肯定每个人都会使用不同的序列化库!
在本章中,我们将遍历所有常见的数据类型,从简单的(有时称为基本数据类型)开始,逐渐过渡到更复杂的类型(如映射和集合)。您应该已经对这些概念大致熟悉,因此重点将不再是每种数据类型的基础知识,而更多地关注在Web API中使用它们时需要考虑的问题。我们将深入研究每种数据类型的不同“陷阱”,以及如何最好地为任何API解决这些问题。我们还将坚持使用JSON作为首选的序列化格式,但大多数建议都适用于支持动态数据结构的任何格式,包括隐式和显式类型定义。让我们从最简单的开始:true 和 false 值。
5.2 布尔类型
在大多数编程语言中,布尔值是最简单的数据类型,表示两个值中的一个:true 或 false。由于这个有限的值集,我们倾向于依赖布尔值来存储标志(flag)或简单的是或否问题。例如,我们可能会在聊天室上存储一个标志,用于指示房间是否已存档或是否允许在房间中使用聊天机器人。
代码5.1 带有布尔标志的聊天室
interface ChatRoom {
id: string;
// ...
archived: boolean;
allowChatbots: boolean;
}
然而,布尔标志在将来的情况下可能会受到限制,其中是或否的问题可能会变成一个更一般的问题,这就需要其他方式能够比布尔字段提供更细致的答案。例如,可能会出现这样的情况,聊天室允许各种不同类型的参与者,而不仅仅是普通用户和聊天机器人。在这种情况下,我们目前的设计将导致一个包含每种允许(或不允许)的类型的长列表,例如 allowChatbots、allowModerators、allowChildren、allowAnonymousUsers 等等。如果这是一种可能性,实际上可能更明智的做法是避免使用一组布尔标志,而是依赖于不同的数据类型或结构来定义哪些参与者被允许或不允许进入特定的聊天室。
假设布尔字段是变量的正确选择,还有一些其他有趣的方面需要考虑。在布尔字段的名称中隐藏着字段是正面还是负面的陈述。在 allowChatbots 的例子中,字段的 true 值表示允许聊天机器人进入聊天室。但它同样可以是 disallowChatbots,其中 true 值将禁止聊天机器人进入聊天室。为什么要选择其中之一呢?
对于大多数人来说,正面的布尔字段最容易理解,原因很简单:人们在处理双重否定时需要花费更多思考。而对于否定字段的 false 值也是如此。例如,想象一下字段是 disallowChatbots。您如何检查在给定的聊天室中是否允许聊天机器人呢?
代码5.2 添加机器人到聊天室
function addChatbotToRoom(chatbot: Chatbot,
roomId: number): void {
let room = getChatRoomById(roomId);
if (room.disallowChatbots === false) {
chatbot.join(room.id);
}
}
这是不是难以理解?可能不是。是否比简单版本(if (room.allowChatbots) { ... })增加了一些认知负担?对于大多数人来说,可能是的。仅仅基于这一点,选择使用正面的布尔标志总是更明智的。但在考虑字段的默认或未设置值时,也存在一些场景可能更适合依赖负面标志。
例如,在某些语言或序列化格式中(例如,直到最近,Google 的 Protocol Buffers v3),许多基础类型,如布尔字段,只能具有零值,而不能是 null 或缺失值。正如您可能猜到的,对于布尔值,零值几乎总是等于 false。这意味着当我们考虑在创建聊天室时的 allowChatbots 字段的值时,如果没有进一步的干预,聊天室不允许聊天机器人(defaultChatRoom.allowChatbots == false)。但我们无法区分用户是否说:“我没有设置这个值,请按照你认为最好的方式处理”(即 null 或缺失值)和“我不想允许聊天机器人”(即明确的 false 值)。在这两种情况下值都只是 false。我们该怎么办呢?
虽然有很多解决这个问题的方法,但一种常见的选择是依赖布尔字段名称的正面或负面特性,以确定“正确”的默认值。换句话说,我们可以选择为布尔字段命名,使得零值提供我们想要的默认值。例如,如果我们希望默认允许匿名用户,我们可以决定将字段命名为 disallowAnonymousUsers,以便零值(false)会导致我们想要的默认值(允许匿名用户)。不幸的是,这种选择将默认值锁定在字段的名称中,这会限制未来的灵活性(即您无法在以后更改默认值),但正如人们所说,非常情况用非常手段。
5.3 数值类型
比起简单的是或否问题,数值字段稍微复杂一些,它们允许我们存储各种有价值的信息,如计数(例如 viewCount)、尺寸和距离(例如 itemWeight)或货币值(例如 priceUsd)。总体而言,任何我们可能想要进行算术计算的内容(即使这些计算只是在逻辑上有意义),数值字段都是理想的数据类型选择。
有一个显著的例外实际上并不适合这种数据类型:数值标识符(ID)。这可能让人感到惊讶,因为许多数据库系统(几乎所有关系数据库系统)使用自动增加的整数值作为行的主键标识符。那么为什么我们在API中不这样做呢?
虽然我们可能出于各种原因(例如性能或空间限制)在底层仍然使用数值字段,但在API界面上,数值类型最适合于可以提供算数方面便利的情景。换句话说,如果API公开的物品具有以克为单位的重量值,我们可以想象将所有这些值相加,以确定这些物品的组合重量。而另一方面,一组数值标识符的相加并不会产生什么意义。因此,重要的是要依赖数值数据类型的数值或算术好处,而不是它们碰巧只用数字字符编写(这里或那里可能有小数点)。通常,那些只看起来像数字但更像令牌或符号的值可能应该是字符串值而不是数值(参见第5.4节)。
话虽如此,在API中使用数值值时,有一些事项需要考虑。让我们首先看看如何定义这些数值字段的可接受值的范围或界限。
5.3.1 界限
在定义数值字段的边界时,无论是整数还是小数(或其他数学表示,如分数、虚数等),都需要考虑上限或最大值、下限或最小值以及零值。由于它们彼此之间存在影响,让我们考虑绝对值边界,然后决定是否利用该范围的负面和正面。
在边界方面,我们主要关注它们的大小。换句话说,所有数字最终都需要存储在某个地方,这意味着我们需要知道为这些值分配多少位的空间。对于小整数,可能8位足够了,有256个可能的值(从-127到127)。对于大多数常见的数字值,32位通常是可接受的大小,有大约40亿个可能的值(从负20亿到正20亿)。对于我们可能关心的大多数情况,64位是一个安全的大小,有大约18万亿个可能的值(从负9万亿到正9万亿)。当我们引入浮点数时,这个范围变得有些混乱,因为有很多不同的表示,存储这些值的位数多达256位,但关键是通常有一种表示方式适用于您在API中考虑的范围。
虽然这些都是可以接受的选择,您可能会想知道为什么我们要关注存储在某个数据库中的数字的大小。毕竟,API的目的不就是要抽象掉所有这些吗?这是正确的;但是,这很重要,因为不同的计算机和不同的编程语言处理数字的方式并不一致。例如,JavaScript甚至没有一个合适的整数值,而是只有一个处理语言所有数值的数字类型。此外,许多语言以非常不同的方式处理非常大的数字。例如,在Python 2中,int类型可以存储32位整数,而long类型可以处理任意大的数字,最少存储36位。简而言之,这意味着如果API响应向消费者发送一个非常大的数字,接收端的语言可能无法正确解析和理解它。此外,那些可能收到这些巨大数字的人需要知道为存储它们分配多少空间。简而言之,边界将非常重要。
因此,通常的做法是在内部使用64位整数类型来处理整数,除非有很好的理由不这样做。一般来说,即使当前可能根本不需要接近64位范围,但在软件中绝对的确定性是罕见的,因此更安全的做法是设置合理上下限,使其具有一定的增长空间。
5.3.2 默认值
如我们在5.1.1节中学到的那样,对于大多数数据类型,我们还有其他情景需要考虑,特别是空值和缺失值。其中字段被简单省略,就像布尔值(5.2节)一样,但在不提供空值的序列化格式中,我们将无法区分0(或0.0)的真值和用户表示“我在这里没有意见,所以你可以为我选择最好的”默认值。
虽然有可能依赖零值作为默认值的标志,但这有一些问题。首先,零值作为API的一部分实际上可能是有意义且是必要的;然而,如果我们将其用作默认值的指示器,我们将无法指定零的实际值。换句话说,如果我们使用0来表示“做最好的选择”(在这种情况下可能是57),我们无法刻意指定零值(因为0用来代表了一种默认情况并映射到其他值)。其次,在零值可能具有逻辑意义的情况下,将此值用作标志可能令人困惑,并导致意外后果,违反了一些良好API的关键原则(在这种情况下是可预测性)。为了回答处理数值的默认值的问题,我们实际上需要转换思路,并更详细地讨论这些值应该如何序列化。
5.3.3 序列化
正如我们在5.3.1节中学到的,一些编程语言对待数值与其他语言不同。这在我们有非常大的数字时特别明显,至少在32位数字以上,但在超过64位限制的数字中更为明显。在处理小数时,由于浮点精度的问题,这也经常出现,这是这种格式设计的众所周知的缺点。
不过,最终我们需要将数值发送给API用户(并从这些用户那里接收传入的数值)。如果我们打算依赖于序列化库而不深入挖掘任何更深层次的东西,那么我们可能会感到非常失望。
代码5.3 两个不同的大数被视为相等
const compareJsonNumbers(): boolean {
// 这两个数字相差1。但是如果我们使用JSON解析后再比较,
// Node.JS会显示他们相等。
const a = JSON.parse('{"value": 9999999999999999999999999}');
const b = JSON.parse('{"value": 9999999999999999999999998}');
return a['value'] == b['value'];
}
这个问题不仅仅局限于大整数。在处理小数时,浮点数算术也存在问题。
代码5.4 两个浮点数相加时的问题
const jsonAddition(): number {
const a = JSON.parse('{"value": 0.1}');
const b = JSON.parse('{"value": 0.2}');
// 很遗憾,这里会返回0.30000000000000004而非0.3
return a['value'] + b['value'];
}
那么我们该怎么办呢?代码5.4中的情况足以表明,使用数值并假设它们在各种语言中都相同可能会让人感到非常担忧。答案可能会让一些纯粹主义者感到沮丧,但它确实效果很好:使用字符串。
这种简单的策略,在序列化时将数值表示为字符串值,只是一种避免这些基本数值被解释为实际数值的机制。相反,这些值本身可以由一个库来解释,该库可能更擅长处理这些类型的情况。换句话说,与其让一个JSON库将0.2解析为JavaScript的Number类型,我们可以使用Decimal.js等库将值解析为任意精度的十进制类型。
代码5.5 避免两个浮点数相加的问题
const Decimal = require('decimal.js');
const jsonDecimalAddition(): number {
// 注意这里的数值是字符串类型
const a = JSON.parse('{"value": "0.1"}');
const b = JSON.parse('{"value": "0.2"}');
// 当我们使用一个类似Decimal.js这样的任意精度函数库,
// 我们可以得到正确的值0.3。
return Decimal(a['value']).add(Decimal(b['value']);
}
由于这种策略的基础依赖于字符串,让我们花一些时间来探讨字符串字段。
5.4 字符串
在几乎所有的编程语言中,我们往往认为字符串是理所当然的东西,而不真正了解它们在底层是如何工作的。即使是那些花时间学习C语言如何处理字符串的人,也倾向于回避字符编码和Unicode的广阔世界。虽然成为Unicode、字符编码或其他与字符串相关的主题的专家并非必须,但在考虑如何在API中处理字符串时,有一些东西是相当重要的。由于API中的大多数字段通常是字符串,这显得尤为重要。
在西方世界,可以相对安全地将字符串视为表示文本内容的单个字符的集合。这是一个相当大的概括,但这不是一本关于Unicode的书籍,因此我们必须概括处理。由于我们想要在API中传达的大部分内容都是文本性质的,字符串可能是所有可用数据类型中最有用的。
在构建API时,字符串也可能是最通用的数据类型。它们可以处理像名称、地址和摘要这样的简单字段;它们可以负责处理长篇文本;在序列化格式不支持通过网络发送原始字节的情况下,它们可以表示编码的二进制数据(例如,Base64编码的字节)。对于存储唯一标识符,字符串也是最合适的选项,即使这些标识符看起来更像是数字而不是文本。在底层可能将它们存储为字节(有关更多信息,请参阅第6章),但在API中的表示几乎肯定最适合使用字符字符串。
在我们开始赞美字符串是世界的救世主之前,让我们花一些时间看看字符串字段的一些潜在陷阱以及我们如何最有效地使用它们,首先是边界条件。
5.4.1 界限
正如我们在第5.3.1节中学到的,边界条件很重要,因为最终我们必须考虑分配多少空间来存储数据。就像在数字值中一样,对于字符串值,我们也需要考虑相同的方面。如果您曾经为关系数据库定义模式(schema),并最终得到了VARCHAR(128)之类的东西,其中的128是一个完全随意的选择,那么您应该对这种有时令人不悦的必要性很熟悉。
正如我们从数字中学到的那样,这些大小限制很重要,因为接收数据的一方需要知道分配多少空间来存储这些值。就像数字一样,由于在API生命周期的早期低估而导致增加大小是一种相当令人不适和不幸的情况。因此,通常最好在选择字符串字段的最大长度时选择向上取整。
然而,值得解决的下一个问题是如何定义最大长度。事实证明,我们最初将字符串定义为字符的集合仅在一些有限的情况下有效,因为许多编程语言并没有像我们期望的那样密切遵循这个概念。然而,更大的问题是,存储空间(磁盘上的字节)的单位与字符串长度的测量单位(我们称之为字符)之间并没有一对一的关系。我们该怎么办呢?
为了避免写一整章关于 Unicode 的内容,对于这个问题的最简单答案是继续以字符为单位思考(即使这些实际上是 Unicode 代码点),然后假设存储使用最冗长的序列化格式:UTF-32。这意味着当我们存储字符串数据时,我们为每个字符分配4个字节,而不是使用 ASCII 时可能期望的单个字节。
尽管存在存储空间的难题,但对于每个字符串字段,我们还需要考虑另一个方面:处理过多的输入。对于数值,超出范围的数字可以被API安全地拒绝,并附上友好的错误消息:“请在0到10之间选择一个值。”对于字符串值,我们实际上有两种不同的选择。我们可以始终拒绝超出范围的值,就像数字超出范围一样,但根据具体情况和上下文,这可能有点不必要。或者,我们可以选择在超出定义的限制后截断文本。
虽然截断可能看起来是个好主意,但它可能会误导和令人困惑,这两者都不是一个好的API的特征,正如我们在第1章中探讨的那样。这还为API引入了一组新的选择(这个字段应该截断还是拒绝?),这可能会导致更多的不可预测性,因为不同的字段展现出不同的行为。因此,与数字一样,通常最明智的做法是拒绝任何超出字段定义限制的输入。
5.4.2 默认值
与数字和布尔字段类似,许多序列化格式并不一定允许存在一个明确的空值(null),与零值("")不同。因此,确定用户是指定字符串为空字符串,还是用户要求API“根据上下文做最好的选择”是很困难的。
幸运的是,有很多选项可供选择。在许多情况下,空字符串根本不是字段的有效值。因此,空字符串确实可以用作指示默认值的标志。在其他情况下,字符串值可能具有一组特定的适当值,空字符串是其中的一种选择。在这种情况下,允许选择 "default" 作为一个标志指示默认值是完全合理的。
5.4.3 序列化
由于 Unicode 标准的普及,几乎所有的序列化框架和编程语言都以基本相同的方式处理字符串。这意味着,与我们在第 5.3 节中探讨的数值值不同,我们的重点不再是精度或微妙的溢出错误,而更多地是安全地处理字符串,这些字符串可能跨越整个人类语言谱系,而不仅仅是西方世界所使用的字符。
在底层,字符串实际上只是一组字节。然而,我们如何解释这些字节(编码)告诉我们如何将它们转换为看起来像实际文本的东西 - 无论我们正在使用的语言是什么。简而言之,这意味着当我们准备在 API 服务器上序列化字符串时,我们不能只是以我们当前使用的任何编码将其发送回去。相反,我们应该在所有请求和响应中始终一致地使用单一的编码格式。
虽然有很多编码格式(例如 ASCII、UTF-8 [https://tools.ietf.org/html/rfc3629]、UTF-16 [https://tools.ietf.org/html/rfc2781] 等),但世界已经趋向于使用 UTF-8,因为它对于大多数常见字符来说相当紧凑,同时仍然灵活到足以编码所有可能的 Unicode 代码点。大多数面向字符串的序列化格式(例如 JSON 和 XML;https://www.w3.org/TR/xml/)已经确定使用 UTF-8,而其他格式(例如 YAML)则没有明确注明必须使用哪种编码。简而言之,除非有很好的理由不这样做,API 应该使用 UTF-8 编码所有的字符串内容。
如果你认为这是一个我们可以让库来处理的地方,你几乎是对的,但还不太对。事实证明,即使在我们指定了一个编码之后,由于 Unicode 的规范化形式 (https://unicode.org/reports/tr15/#Norm_Forms),仍然有多种方法来表示相同的字符串内容。可以将其视为表示数字 4 的各种方式:4、1+3、2+2、2*2、8/2 等。在 UTF-8 编码的字符串中,可以使用相同的二进制表示方式。例如,字符 “è” 可以表示为单个特殊字符 (“è” 或 0x00e9),也可以表示为基本字符 (“e” 或 0x0065) 与重音字符 (“`” 或 0x0301) 的组合。这两种表示在视觉和语义上是相同的,但它们在磁盘上的字节表示不同,因此对于进行精确匹配的计算机来说,它们是完全不同的值。
为了解决这个问题,Unicode (http://www.unicode.org/versions/Unicode13.0.0/) 支持不同的规范化形式,并且一些序列化格式(例如 XML)标准化了特定的形式(在 XML 的情况下,规范化形式 C),以避免混合和匹配这些在语义上相同的文本表示。尽管这对于表示 API 资源描述的字符串可能没有那么重要,但当字符串表示标识符时,这变得非常重要。如果标识符具有不同的字节表示,那么可能相同的语义标识符实际上指的是不同的资源。因此,API 最好拒绝不使用规范化形式 C 进行 UTF-8 编码的字符串,而对于表示资源标识符的字符串来说,这是绝对必要的。有关标识符及其格式的更多信息,请参阅第 6 章。
5.5 枚举类型
枚举类型(Enumerations), 类似于程序员的下拉选择器,是强类型编程语言世界中的基本元素。虽然在诸如Java之类的语言中它们可能非常有用,但将它们移植到Web API的世界中通常是一个错误。
虽然枚举可能非常有价值,因为它们既充当验证的形式(只有指定的值被视为有效),又具有压缩性(通常每个值由一个数字表示,而不是我们在代码中引用的文本表示),但当涉及到Web API时,这两个方面通常是有代价的,即降低了灵活性和清晰度。
代码5.6 在API中的枚举类型
enum Color {
Brown = 1,
Blue,
Green,
}
interface Person {
id: string;
name: string;
eyeColor: Color;
}
例如,让我们考虑列表5.6中的枚举。如果我们使用真实的整数值,我们可能最终会得到 person.eyeColor 被设置为 2。显然,这比 person.eyeColor 被设置为 "blue" 更加混乱,因为前者要求我查找数字值的实际含义。在代码中,这通常不是问题;然而,在查看请求日志时,这可能变得相当繁琐。
此外,当服务器上添加新的枚举值时,客户端将需要更新其本地映射的副本(通常需要更新客户端库),而不仅仅是发送不同的值。更可怕的是,如果API决定添加一个新的枚举值,而客户端没有被告知该值的含义,客户端代码将感到困惑并不知道该怎么办。
例如,考虑API添加了一个名为 Hazel (#4) 的新颜色值的情况。除非客户端代码已更新以适应这个新值,否则我们可能会陷入一个相当令人困惑的场景。另一方面,如果我们使用不同类型的字段(比如字符串),我们可能会由于先前未知的值而遇到类似的错误,但我们不会被该值的含义所困扰("hazel"比4更清晰)。
简而言之,在可以使用其他类型(比如字符串)的情况下,通常应避免使用枚举。当预计会添加新值时,尤其是当存在该值的某种标准时,这一点尤为真实。例如,与其使用枚举来表示有效的文件类型(PDF、Word文档等),更安全的做法是使用一个允许特定媒体类型(以前称为MIME类型)的字符串字段,如 application/pdf 或 application/msword。
5.6 列表
现在我们对各种基本数据类型有了一定的了解,我们可以开始深入研究这些数据类型的集合,其中最简单的是列表或数组。简而言之,列表只不过是一组其他数据类型,例如字符串、数字、映射(参见第5.7节)或甚至其他列表。这些集合通常可以通过索引或在列表中的位置进行访问,使用方括号表示法(例如,items[2]),并且几乎所有的序列化格式都支持这种表示(例如,JSON)。
虽然并非所有存储系统都原生支持项目列表,但请记住,API的目标是为远程用户提供最有用的接口,而不是暴露数据库中的数据。话虽如此,列表是当今Web API中最常被误用的结构之一。那么何时应该使用列表呢?
总的来说,列表非常适用于简单的基本集合,这些集合代表API资源的某些固有属性。例如,如果您有一个“Book(书)”资源,您可能希望显示关于该书的一系列类别或标签,这可能最好表示为一个字符串列表。
代码5.7 在Book资源中存储一个类别列表
interface Book {
id: string;
title: string;
categories: string[];
}
5.6.1 原子性
上个例子中隐藏着一些很重要的内容:尽管列表字段包含多个项目,但最好将这些项目被视为数据的一个原子部分,在使用时进行完全替换而不是分开修改。换句话说,如果我们想要更新“Book”资源上的类别(categories),我们应该通过完全替换其项目列表来实现。换句话说,在列表字段中永远不应该有更新单个元素的方式。这其中有许多很好的理由,比如当我们通过它们在列表中的位置来引用项目时,顺序变得非常重要;或者我们可能不能保证插入新项目时,不会将感兴趣的项目推到一个新的位置。
此外,与资源上的任何其他字段一样,允许数据从两个不同的地方存储和修改几乎总是一个坏主意,因此最好避免允许多种方法更新列表字段中的内容。这是一种特别诱人的做法,因为我们在关系数据库中被训练依赖规范化原则。例如,如果我们使用像MySQL这样的数据库存储“Book”资源上的这个类别列表,我们实际上可能会有一个单独的“BookCategories”表,具有唯一标识符、指向书籍的外键以及一个具有唯一性约束的类别字符串。很多人忍不住想要通过公开一个API来允许通过提供书籍的唯一ID和我们要编辑的类别来更新这些图书类别(因为在技术上这足以唯一标识所涉及的行)。
允许这种修改方式会引发与一致性相关的一系列令人担忧的问题:有可能在某人设置类别列表的同时,另一个人正在使用不同的入口编辑单个类别。在这种情况下,即使依赖于其他事务隔离机制(例如ETags),也不会有太多用处,会导致API充满了意外。
对于列表值的一个良好的经验法则是几乎将它们视为实际上是项目的JSON编码字符串。换句话说,你不是在设置book.categories = ["history", "science"],而是更接近book.categories = "[\"history\", \"science\"]"。你不会期望API允许你修改字符串中的单个字符,所以也不要期望API允许你修改列表字段中的单个条目。
有关资源及其相互关系的更多探讨,请参阅第4部分,特别是第13、14和15章,它们都涉及使用列表字段在Web API中表示关系数据的概念。
下一步需要考虑的是列表是否应该允许在同一个列表中混合不同的数据类型。换句话说,是否在同一个列表中混合使用字符串值和数字值是个好主意?虽然这样做并非完全不可行,但可能会导致一些混淆,特别是考虑到第5.3.3节关于处理大数字和小数的指导。这些值可能被表示为字符串,因此很难弄清楚给定的条目实际上是字符串还是仅以字符串表示的数值。基于此,通常最好坚持使用单一数据类型,并保持列表值的同质性。
5.6.2 界限
最后,关于列表值的一个非常常见的情景涉及到大小:当列表变得很长以至于难以管理时会发生什么?为了避免这种令人沮丧的情况,所有的列表都应该有一些界限,指定它们可能具有的最大项数以及每个项可能的大小(参见第5.3.1或5.4.1节,了解如何处理数值和字符串数据类型的界限)。此外,超出这些边界的输入应该被拒绝而不是被截断(原因与第5.4.1节中解释的相同)。这有助于避免因异常庞大的列表而产生的意外和困惑,这些列表可能会意外地增长到难以处理的大小。
如果很难估算列表的潜在大小,或者有充分的理由怀疑它可能会在没有硬性边界的情况下增长,那么依赖于实际资源的子集合而不是资源上的内联列表可能是一个不错的主意。虽然这可能看起来很繁琐,但在未来,当资源不会因为无界列表字段而变得庞大时,API将更加易于管理。然而,如果你陷入了这个境地,可以查看分页模式(第21章),它可以帮助将庞大且难以处理的资源转化为更小且易于处理的块。
5.6.3 默认值
与字符串类似,在某些序列化格式和库中,很难区分零值(对于列表是[])和空值。然而,与字符串不同的是,将空列表作为值几乎总是合理的,这使得API几乎不可能依赖于空列表值来表示请求使用某个默认值而不是空列表。这给我们留下了一个复杂的问题:在这种情况下,如何指定你希望该值是默认值而不是字面上的空列表?
不幸的是,在这类情况下似乎没有任何简单而优雅的答案。要么可以在创建时使用默认值(假设空列表对于新创建的资源来说是无效的),要么列表值根本不是此信息的正确数据类型。如果前一种情况由于某种原因不起作用,唯一的安全选择是抛弃使用內联列表类型,并将这些数据作为集合由子资源分开管理。显然,这不是一个理想的解决方案,但鉴于限制,它肯定是最安全的选择。
5.7 映射
最后,我们可以讨论最多功能且有趣的数据类型:映射(Map)。在本节中,我们将实际考虑两种相似但不同的基于键值的数据类型:自定义数据类型(我们一直称之为资源或接口)和动态键值映射(通常是JSON中称为对象或映射的东西)。尽管这两者并不相同,它们之间的区别有限,主要区别在于是否存在预定义的模式(schema)。换句话说,映射是键值对的任意集合,而自定义数据类型或子资源可能以相同的方式表示;然而,自定义数据类型具有一组预定义的键以及特定类型的值。让我们首先看看具有预定义模式的那种。
随着资源演变以表示越来越多的信息,一个典型的步骤是将相似的信息组合在一起,而不是保持一切都是扁平的。例如,随着我们为ChatRoom资源添加越来越多的配置,我们可能决定将其中一些配置字段组合在一起。
代码5.8 直接在资源中存储数据,以及将数据存储在其他的结构中
// 所有字段直接扁平化存储在资源中
interface ChatRoomFlat {
id: string;
name: string;
password: string;
requirePassword: boolean;
allowAnonymousUsers: boolean;
allowChatBots: boolean;
}
// 把访问聊天室相关的字段存储到其他结构中
interface ChatRoomReGrouped {
id: string;
name: string;
securityConfig: SecurityConfig;
}
interface SecurityConfig {
password: string;
requirePassword: boolean;
allowAnonymousUsers: boolean;
allowChatBots: boolean;
}
在这种情况下,我们只是根据它们对控制安全性和访问聊天室的共同主题,将几个字段简单地组合在一起。这种抽象层次只有在我们真正考虑将资源的相似字段组合在一起时才有意义。另一方面,如果字段与资源相关但在资源的上下文之外基本上是不同且有意义的,那么使用单例子资源可能是值得的,详情请参阅第12章。
现在我们已经探讨了具有预定义模式的自定义数据类型,让我们花一点时间来看看动态键值映射。尽管它们最终可能以相同的方式呈现,但这两种结构通常以非常不同的方式使用。而我们使用自定义数据类型将相似字段折叠在一起并将其隔离在单个字段中,动态键值映射更适合存储没有预期结构的任意动态数据。换句话说,自定义数据类型只是一种重新排列我们知道的字段并希望更好地组织的方法,而映射更适合带有在定义API时未知的键的动态键值对。此外,虽然这些键可能会在资源之间有一些重叠,但绝对不要求像自定义数据类型一样,所有资源必须有相同的键。
这种键值对的任意结构非常适合诸如动态设置或依赖于资源特定实例的配置之类的事物。为了了解这意味着什么,想象一下我们有一个用于管理杂货店商品信息的API。我们显然需要一种方法来说明每个产品中包含的成分以及其数量,例如3克糖、5克蛋白质、7毫克钙等。使用预定义架构列出所有可能的成分将是非常困难的,即使我们能够做到这一点,这些项的许多值将为零,因为每个项都有各种不同的成分。在这种情况下,动态映射可能是最合适的。
代码5.9 使用动态映射存储配方成分和数量
interface GroceryItem {
id: string;
name: string;
calories: number;
ingredientAmounts: Map<string, string>;
}
使用定义的模式,GroceryItem的JSON表示可能类似于代码5.10。在这种情况下,成分是动态的,并且可以随每个不同的项目而变化。
代码5.10 配方成分映射的JSON表示示例
{
"id": "514a0119-bc3f-4e3f-9a64-8ad48600c5d8",
"name": "Pringles",
"calories": "150",
"ingredientAmounts": {
"fat": "9 g",
"sodium": "150 mg",
"carbohydrate": "15 g",
"sugar": "1 g",
"fiber": "1 g",
"protein": "1 g"
}
}
重要的是要注意,由于我们可以选择键的数据类型,原则上我们可以选择任何类型。但是某些类型的选择可能会是灾难性的(例如,一些不容易序列化的富数据类型)。其他可能看起来可以接受,但仍然是一个坏主意。例如,技术上允许数字值作为键类型可能有一定道理;然而,正如我们在第5.3.3节中了解到的那样,数字存在一些相当危险的问题,特别是当它们变大时,有时甚至只是小的十进制值也可能存在问题。因此,在键的数据类型中,字符串几乎肯定是最好的选择。
更重要的是,由于键是唯一的标识符,因此这些字符串值以UTF-8格式编码也很重要,并且正如我们在第5.4.3节中学到的(并且将在第6章中更多了解),这些字符串应该处于规范化分解(Normalization Form C),以避免由于字节表示问题导致的重复键值。
5.7.1 界限
自定义数据类型的模式避免了任何边界问题(其模式定义了自己的边界条件),而映射与列表非常相似,因为它们都很容易失控。因此,映射(就像列表一样)应该定义一个上限,规定字段中可能包含多少个键和值。这在设定字段内容可能增长到多大的期望方面变得非常重要。除此之外,还有必要设置每个键和每个值可以作为字符串值的大小限制(有关字符串值边界的更多信息,请参见第5.4.1节)。一般来说,这意味着指定一个键最多可能有大约100个字符,而值最多可能有大约500个字符。
在极少数情况下,值的大小可能分布不太均匀。因此,一些API选择对映射字段中存储的字符总数设定上限,允许用户自由决定如何表示这些不同的字符(一些非常小的值和一两个非常大的值)。虽然如果绝对必要,这是一种可接受的策略,但应该避免使用,因为它往往会导致越来越多的数据最终存储在映射中,而这些数据可能本来应该存储在其他地方。
5.7.2 默认值
与列表不同,在几乎所有序列化格式和编程语言中,很容易区分空映射值或零值({})和空值(null)。在这种情况下,让空值表示“API应根据API请求的其余部分执行其认为最好的操作”是相当安全的。另一方面,空映射是用户指定映射不应包含任何数据的方式,这本身就是一个有意义的表示。
5.8 练习
- 日本一家面向日语使用者的公司希望在其API的字符串字段中使用UTF-16编码而不是UTF-8。在做出此决定之前,他们应该考虑什么?
- 假设ChatRoom资源当前会存档24小时前的所有消息。如果要提供一种禁用此行为的方法,应该如何命名该字段?这种设计是最佳实践吗?
- 如果您的API是用本地支持任意大数的语言编写的(例如Python 3),将它们序列化为JSON字符串仍然是最佳实践吗?还是可以依赖于标准的JSON数字序列化?
- 如果要表示聊天室的母语,是否可以使用枚举值来表示支持的语言?如果可以,这个枚举会是什么样子?如果不行,什么数据类型最合适?
- 如果特定的映射的值大小分布非常不均匀,设置各个键和值的适当大小限制的最佳方法是什么?
本章总结
- 对于每个值,我们还需要考虑null值和未定义或缺失值,它们可能具有相同或不同的含义。
- 布尔值最适合用于标志,并且应命名为true值表示积极方面(例如,使用enableFeature而不是disableFeature)。
- 数值应具有真正的数值含义,而不仅仅由数字位组成。
- 为避免大数字(超过32或64位)或浮点算术问题,不具备适当本地表示的语言中,数值应以字符串形式序列化。
- 字符串应以UTF-8编码,并对任何用作任何标识符的字符串进行Normalization Form C规范化。
- 通常应避免使用枚举,而应使用字符串值,并在服务器端而不是客户端上进行验证。
- 列表应被视为原子集合项,仅在客户端上可以单独寻址。
- 列表和映射都应受到允许集合中的项目总数的限制;但是,映射还应该限制键和值的大小。